LangChain 学习
LangChain: 一个让你的LLM变得更强大的开源框架。LangChain 就是一个 LLM 编程框架,你想开发一个基于 LLM 应用,需要什么组件它都有,直接使用就行;甚至针对常规应用流程,利用Chain(链)内置标准化方案。
LangChain是一个基于语言模型开发应用程序的框架。它可以实现
- 数据感知:将语言模型连接到其他数据源
- 自主性:允许语言模型与其环境进行交互
LangChain 为特定用例提供了多种组件,例如个人助理、文档问答、聊天机器人、查询表格数据、与 API 交互、提取、评估和汇总。 通过提供模块化和灵活的方法简化了构建高级语言模型应用程序的过程。通过了解组件、链、提示模板、输出解析器、索引、检索器、聊天消息历史记录和代理等核心概念,可以创建适合特定需求的自定义解决方案。 LangChain 能够释放语言模型的全部潜力,并在广泛的用例中创建智能的、上下文感知的应用程序。
LangChain六大主要领域
- 管理和优化prompt。不同的任务使用不同的prompt,如何去管理和优化这些prompt是langchain的主要功能之一。
- 链,一个具体任务中不同子任务之间的一个调用
- 数据增强的生成。数据增强生成设计特定类型的链,首先与外部数据源交互以胡哦去数据用于生成步骤。
- 代理,根据不同的指令采取不同的行动,直到整个流程完成为止。
- 评估,生成式模型难以用传统指标来评估。评估它们的新方法是使用语言模型本身来评估
- 内存,在整个流程中管理一些中间状态
总的来说LangChain可以理解为:在一个流程的整个生命周期中,管理和优化prompt,根据prompt使用不同的代理进行不同的动作,在这期间使用内存管理中间的一些状态, 然后使用链将不同代理之间进行连接起来,最终形成一个闭环。
LangChain的主要价值
- 组件:为使用语言模型提供抽象层,以及每个抽象层的一组实现。用于处理语言模型的抽象概念,以及每个抽象概念的实现集合。组件是模块化的,易于使用。
- 链:用于完成特定高级任务的组件的结构化组合。
LangChain组件
- model I/O:语言模型接口,包括对大语言模型输入输出的管理,输入环节的提示词管理(包含模板化提示词和提示词动态选择等),处理环节的语言模型(包括所有LLMs的通用接口,以及常用的LLMs工具;Chat模型是一种与LLMs不同的API,用来处理消息),输出环节包括从模型输出中提取信息。
- data connection:与特定任务的数据接口
- chains:构建调用序列
- agents:给定高级指令,让链选择使用哪些工具
- memory:在一个链的运行之间保持应用状态
- callbacks:记录并流式传输任何链的中间步骤
- indexes:索引指的是结构化文件的方法,以便LLM能够与其进行最好的交互。
提示词管理
- 提示模板 动态提示词=提示模板+变量,通过引入给提示词引入变量的方式,一方面保证了灵活性,一方面又能保证Prompt内容结构达到最佳
系统设置了三种模板:固定模板不需要参数,单参数模板可以替换单个词,双参数模板可以替换两个词。
比如单参数模板可以提问"告诉一个形容词笑话"。运行时传入"有意思"作为参数,就变成"告诉一个有意思的笑话"。
双参数模板可以提问"某个形容词关于某内容的笑话"。运行时传入"有趣","鸡"作为参数,就变成"告诉一个有趣的关于鸡的笑话"。
通过设置不同模板和参数,一套系统就可以自动生成各种问题,实现智能对话与用户互动。
- 聊天提示模板 聊天场景中,消息可以与AI、人类或系统角色相关联,模型应该更加密切地遵循系统聊天消息的指示。 这个是对 OpenAI gpt-3.5-tubor API中role字段(role 的属性用于显式定义角色,其中 system 用于系统预设,比如”你是一个翻译家“,“你是一个写作助手”,user 表示用户的输入, assistant 表示模型的输出)的一种抽象,以便应用于其他大语言模型。SystemMessage对应系统预设,HumanMessage用户输入,AIMessage表示模型输出,使用 ChatMessagePromptTemplate 可以使用任意角色接收聊天消息。
系统会先提示“我是一个翻译助手,可以把英文翻译成中文”这样的系统预设消息。
然后用户输入需要翻译的内容,比如“我喜欢大语言模型”。
系统会根据预先定义的对话模板,自动接受翻译语种和用户输入作为参数,并生成对应的用户输入消息。
最后,系统回复翻译结果给用户。通过定制不同对话角色和动态输入参数,实现了模型自动回复用户需求的翻译对话。
- 基于 StringPromptTemplate 自定义提示模板StringPromptTemplate
- 将Prompt输入与特征存储关联起来(FeaturePromptTemplate)
- 少样本提示模板(FewShotPromptTemplate)
- 从示例中动态提取提示词✍️
LLM
- 流式传输功能,能即时逐字返回生成内容,还原聊天过程
- 回调追踪token使用,了解模型耗费情况
- ChatModel支持聊天消息作为输入,生成回应完成对话
- 配置管理可以读取保存LLM设置,方便重复使用
- 提供模拟工具代替真实模型,在测试中减少成本
- 与其他AI基础设施无缝融合
数据连接器data connection
LLM应用需要用户特定的数据,这些数据不属于模型的训练集。LangChain通过以下方式提供了加载、转换、存储和查询数据的构建模块:
- 文档加载器:从许多不同的来源加载文档
- 文档转换器:分割文档,删除多余的文档等
- 文本嵌入模型:采取非结构化文本,并把它变成一个浮点数的列表 矢量存储:存储和搜索嵌入式数据
- 检索器:查询你的数据
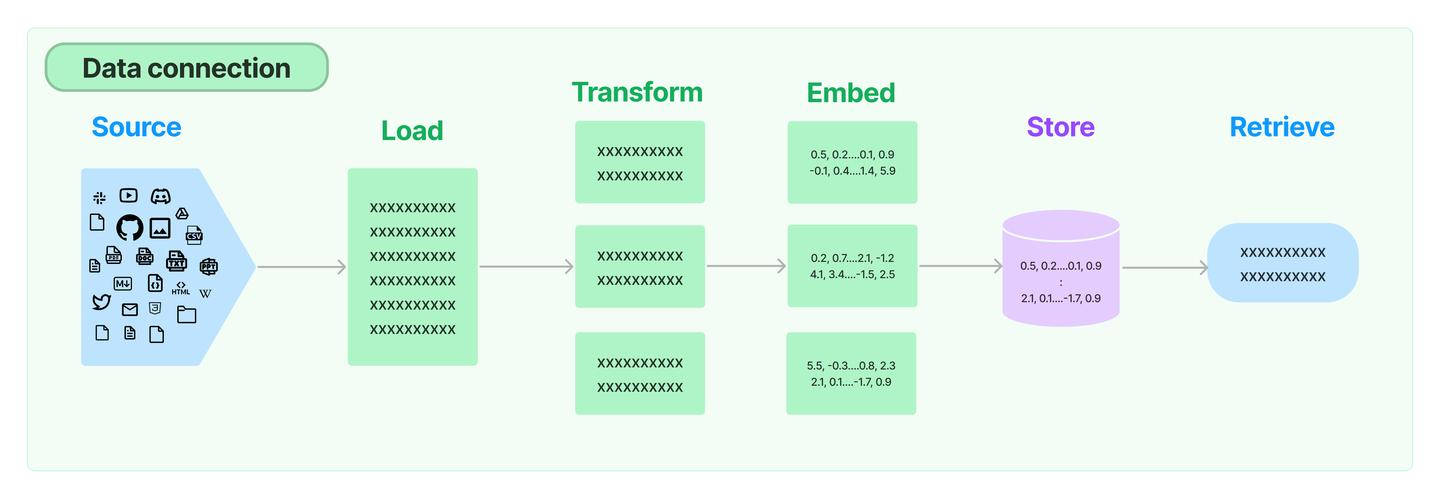
文档加载
重点包括了csv(CSVLoader),html(UnstructuredHTMLLoader),json(JSONLoader),markdown(UnstructuredMarkdownLoader)以及pdf (因为pdf的格式比较复杂,提供了PyPDFLoader、MathpixPDFLoader、UnstructuredPDFLoader,PyMuPDF等多种形式的加载引擎)几种常用格式的内容解析, 但是在实际的项目中,数据来源一般比较多样,格式也比较复杂,重点推荐按需去查看与各种数据源 集成的章节说明,Discord、Notion、Joplin,Word等数据源。
文档转换器
加载了文件后,经常会需要转换它们以更好地适应应用。最简单的例子是,你可能想把一个长的文档分割成较小的块状,以适应你的模型的上下文窗口。 LangChain有许多内置的文档转换工具,可以很容易地对文档进行分割、组合、过滤和其他操作。
- 通过字符进行文本分割:设置分块的字符长度和重合的文本长度
- 对代码进行分割
- 通过markdownheader进行分割:定义分割头,文本会被分割头进行分割
- 通过字符递归分割:按指定顺序的分隔符列表,对字符串进行 “逐层递进的多次分割”—— 后一次分割的输入,是前一次分割的输出结果,最终将字符串拆成细粒度的元素。
- 通过tokens个数进行分割
文本嵌入算法
文本嵌入算法是指将文本数据转化为向量表示的具体算法,通常包括以下几个步骤:
- 分词:将文本划分成一个个单词或短语。
- 构建词汇表:将分词后的单词或短语建立词汇表,并为每个单词或短语赋予一个唯一的编号。
- 计算词嵌入:使用预训练的模型或自行训练的模型,将每个单词或短语映射到向量空间中。
- 计算文本嵌入:将文本中每个单词或短语的向量表示取平均或加权平均,得到整个文本的向量表示。
常见的文本嵌入算法包括 Word2Vec、GloVe、FastText 等。这些算法通过预训练或自行训练的方式,将单词或短语映射到低维向量空间中,从而能够在计算机中方便地处理文本数据。
文本嵌入用于测量文本字符串的相似性,通常用于:
- 搜索(结果按与查询字符串的相关性排序)
- 聚类(其中文本字符串按相似性分组)
- 推荐(推荐具有相关文本字符串的项目)
- 异常检测(识别出相关性很小的异常值)
- 多样性测量(分析相似性分布)
- 分类(其中文本字符串按其最相似的标签分类)
模型IO组件
LangChain提供了连接任何语言模型的构建模块。
提示: 模板化、动态选择和管理模型输入
提示语是 “给 AI 模型编程的新方式”—— 不用写传统代码,而是通过 “结构化输入” 引导模型输出;而 LangChain 的核心作用,就是用 “提示模板” 和 “例子选择器” 这两个工具, 帮你更高效、灵活地构建这种结构化输入。
一个提示模板可以包含:对语言模型的指示;一组少量的例子,以帮助语言模型产生一个更好的反应;一个对语言模型的问题。
语言模型: 通过通用接口调用语言模型
LangChain中的LLM指的是纯文本完成模型。它们所包含的API将一个字符串提示作为输入并输出一个字符串完成。
常见的方法 "predict "和 "pred messages",前者接受一个字符串并返回一个字符串,后者接受消息并返回一个消息。
使用LLM的最简单方法是可调用:传入一个字符串,得到一个字符串完成。
generate: batch calls, richer outputs
generate让你可以用一串字符串调用模型,得到比文本更完整的响应。这个完整的响应可以包括像多个顶级响应和其他LLM提供者的特定信息。
LongChain具体支持什么模型,不同模型是怎么使用的可以看官方文档:Language models | ️ Langchain
输出分析器: 从模型输出中提取信息
输出解析器是帮助结构化语言模型响应的类。有两个主要的方法是输出解析器必须实现的:
- "获取格式说明":该方法返回一个字符串,包含语言模型的输出应该如何被格式化的指示。
- "解析": 该方法接收一个字符串(假定是来自语言模型的响应)并将其解析为某种结构。
- "带提示的解析":该方法是可选方法,它接收一个字符串(假定是来自语言模型的响应)和一个提示(假定是产生这种响应的提示),并将其解析为一些结构。提示主要是在OutputParser想要重试或以某种方式修复输出的情况下提供的,并且需要从提示中获得信息来这样做。
具体通过格式化指令和自定义方法两种方式。
具体见Output parsers | ️ Langchain
Chain链组件
更复杂的应用需要将LLM串联起来--要么相互串联,要么与其他组件串联。这时就需要用到Chain链组件。
LangChain为这种 "链式 "应用提供了Chain接口,基本接口很简单:
class Chain(BaseModel, ABC):
"""Base interface that all chains should implement."""
memory: BaseMemory
callbacks: Callbacks
def __call__(
self,
inputs: Any,
return_only_outputs: bool = False,
callbacks: Callbacks = None,
) -> Dict[str, Any]:
...
使用不同链功能的演示,可参见官方文档.
链允许我们将多个组件结合在一起,创建一个单一的、连贯的应用程序。例如,我们可以创建一个链,接受用户输入,用PromptTemplate格式化,然后将格式化的响应传递给LLM。 我们可以通过将多个链组合在一起,或将链与其他组件组合在一起,建立更复杂的链。LLMChain是最基本的构建块链。它接受一个提示模板,用用户输入的格式化它,并从LLM返回响应。