幸运营销汇-开发日志-第一阶段
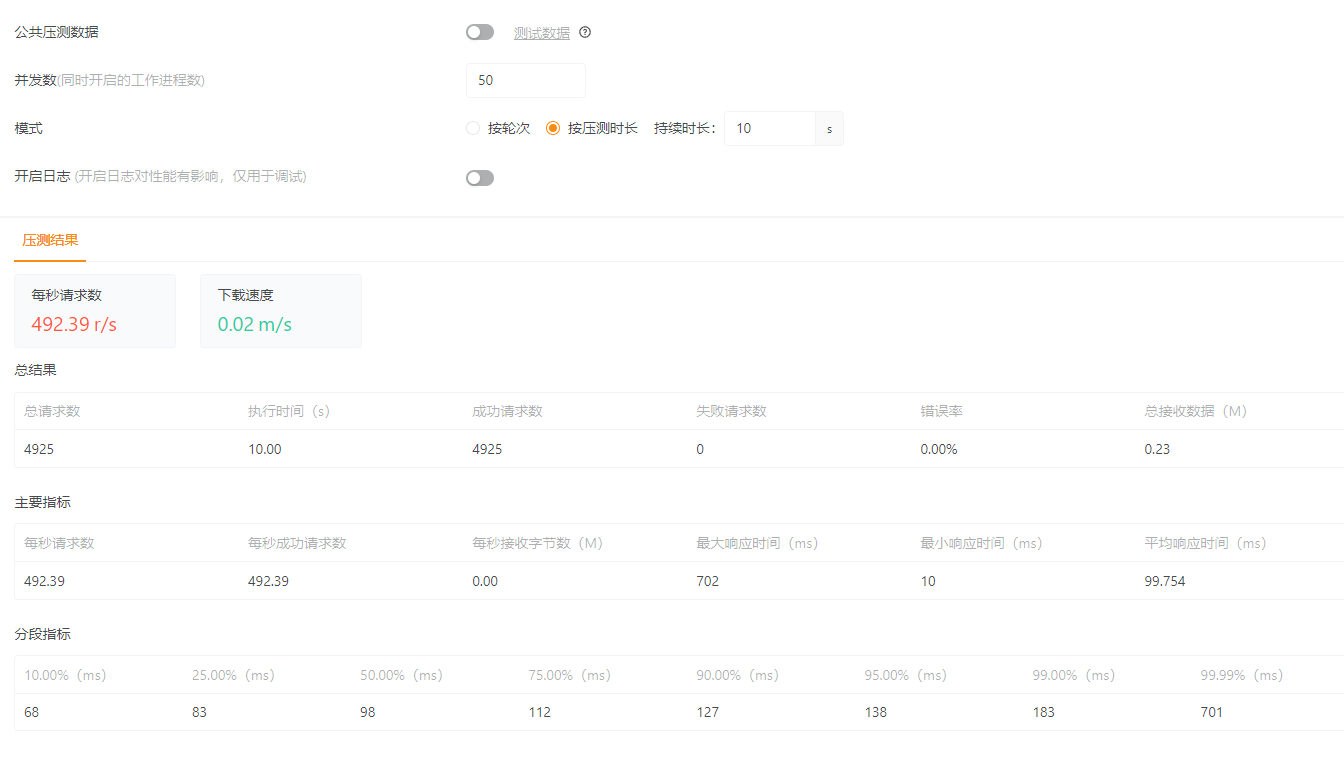
幸运营销汇-积分抽奖服务是我独立负责实现的一个学习项目,参考了拼多多、稀土掘金社区的营销抽奖方案, 构建一个高可用、高扩展、易维护的营销抽奖平台,实现了多场景抽奖、用户行为返利(签到)、积分账户体系以及积分兑换等核心功能。 项目模块在架构设计上运用了 DDD 分层架构和模板模式、责任链模式、组合模式、工厂模式等,设计模式对业务流程进行解耦和实现, 利用责任链、组合模式构建可配置的规则引擎,提升系统的灵活性。设计“无锁化”库存扣减方案,解决超卖问题, 通过延迟消息+定时任务异步、批量更新数据库来保证数据最终一致性,降低了数据库压力,提升系统性能。实施分库分表与数据同步方案,支撑系统扩展。 在4C8G的服务器上,经过JMeter压测,系统成功支撑了单机近600 TPS的抽奖请求,平均响应时间在300ms左右。 在极端高并发下,响应时间的长尾现象(99%线较高)仍有优化空间,未来可考虑进一步优化JVM GC参数,或对热点数据做更极致的本地缓存。 目前分库分表组件为自研,功能上虽满足需求,但在易用性和生态整合上对比ShardingSphere等成熟产品有差距,后续可考虑平滑迁移。 在各类营销产品上都可以添加抽奖模块,增加用户粘性。
抽奖系统以“装配—参与—抽奖—结算”四段式流程为主线:
- 首先,活动装配阶段会把目标活动的基础信息、SKU 库存与SKU发放策略、奖品清单及其概率散列表(若规则中包含积分决定奖品,则将积分-奖品散列表一并)统一加载进 Redis。 装配完成后,用户可通过购买、签到等多种 SKU 活动累积抽奖次数;系统会验证 SKU 活动是否处于有效期、库存是否充足,校验通过后在一个事务内同时为用户增加账户总额度,并在 raffle_activity_order 表写入流水,确保额度与订单原子一致。
- 当用户发起抽奖请求时,系统先校验活动可用性,再查询是否存在状态为 noused 的待抽奖订单;若存在直接返回,否则按“总额度-月额度-日额度”三级维度顺序扣减,并生成 user_raffle_order 记录。 扣减过程中,SKU 库存以 Redis 原子扣减为准,扣到 0 时异步发布消息回刷数据库;奖品库存则是在 Redis 扣减后通过 MQ 触发单件落库,避免超卖(缓存中也采用商品库存槽位锁来兜底)。
- 抽奖逻辑分三段:抽奖前、抽奖中、抽奖后。抽奖前根据活动 ID 动态装配责任链:若未定制链,则走默认链;若链中配置了黑名单、积分权重等节点,则优先判定——命中黑名单或已由积分直接命中奖品时,流程短路直接返回,不再进入后续规则树。 若责任链放行,进入抽奖后阶段的规则树处理。抽奖后通过活动-规则树 ID 建立树根、节点、边的有序结构,装配规则引擎并逐节点校验次数门槛、库存阈值等条件;若某一步校验失败则走幸运奖兜底,具体奖项依数据库配置而定。
- 当最终中奖结果产生,系统会把 user_raffle_order 状态更新为 used,并把中奖内容写入 user_award_account ;随后异步发送 MQ 消息通知下游做奖品发放,并在任务表写入一条补偿任务,以便消息丢失时可定时重推,保证全链路一致性与可恢复性。
整体方案以领域分层(domain、infrastructure、trigger)、责任链 + 规则树双层过滤、Redis 原子扣减 + MQ-Task 最终一致、事务保障一致四大技术手段,确保高并发下的抽奖正确性与库存安全
项目地址:
- 前端:https://github.com/orbisz/big_market_front
- 后端:https://github.com/orbisz/big_market
领域拆分: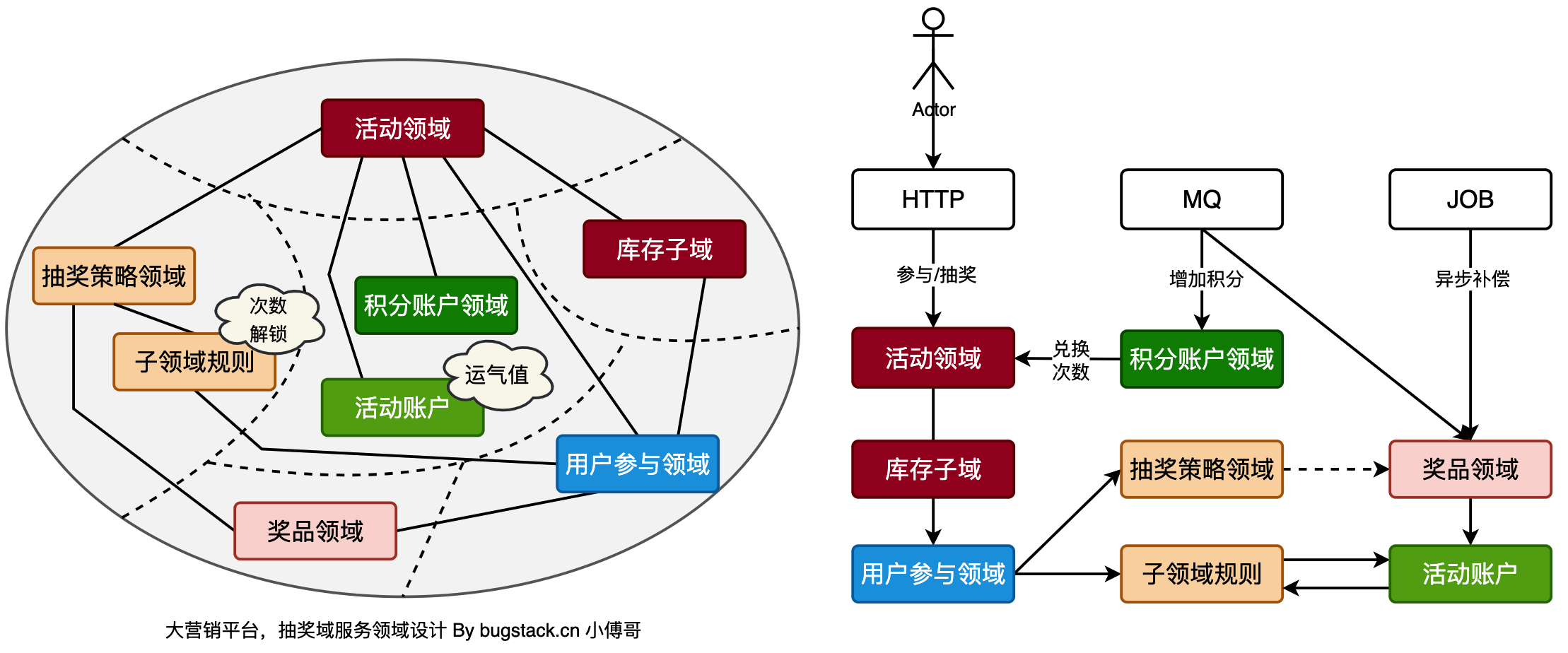
库表设计
分析大营销平台中抽奖的产品功能,设计抽奖策略模型和库表结构。根据以下需求来完成库表设计
- 整体概率相加,总和为 1,概率范围千分位
- 抽奖为免费抽奖次数 + 用户消耗个人积分抽奖
- 抽奖活动仓库库存,控制运营成本(可配置无限制库存)
- 活动延伸配置用户库存消耗管理,单独提供表配置各类库存用户可用总库存、用户可用日库存
- 部分抽奖规则,需要抽奖 n 次后解锁,才能有机会抽取
- 抽奖完成增加运气值记录,让用户获得奖品。
- 奖品对接,自身的积分、内部系统的奖品 随机积分,发给你积分。
利用Docker维护MySql数据库,建立起以下数据表
策略总表
- 抽象与归一化管理抽奖逻辑:一套抽奖策略可以管理多个奖品,并且定义奖品分布、概率等核心规则。
- 作为策略主键表:为其它抽奖子模块(如奖品明细、规则配置)提供外键关联支撑,成为整个抽奖逻辑的锚点。
- 支持扩展性与维护性:通过对策略描述等字段的设计,可以便于后续开发维护和功能扩展。
- 用户进入抽奖系统,前端请求接口时,会携带 strategy_id。
后端根据 strategy_id 读取策略定义、查找对应的奖品配置和抽奖规则(通常联表查 strategy_award, strategy_rule)。 若未来需要对策略进行版本管理或灰度测试,也可以基于 strategy_id 做策略路由与控制。
策略奖品
- 实现抽奖策略与奖品的映射关系:每条记录代表一个奖品在某一抽奖策略下的配置情况。
- 支撑概率抽奖逻辑:通过 award_rate 定义奖品概率,支持后端概率算法实现。
- 具备奖品库存控制能力:通过库存总量与剩余字段,控制奖品是否还能继续发放。
- 支持策略规则模型挂载:通过 rule_models 字段灵活绑定规则,支持扩展与组合
strategy_award 表是 连接抽奖策略与奖品的配置核心,通过抽象奖品信息、概率、库存和规则模型,为策略提供 灵活可控、可扩展的奖池构建能力。
策略规则
为抽奖系统提供:
- 高度灵活的规则配置机制
- 支持奖品粒度的个性化抽奖逻辑
- 抽象策略层与奖品层规则的统一管理
- 可扩展的“规则模型”体系
strategy_rule 表通过高度抽象的“规则模型 + 参数”设计,实现了抽奖系统策略逻辑的模块化、可配置、可扩展、可复用,是整个系统灵活性的核心支撑点
奖品表
- 抽象定义所有奖品及其配置
- 支持 不同类型奖品(积分、次数、模型等)
- 为系统发奖逻辑提供 统一的数据支撑
- 与规则系统(如 strategy_rule 表)配合,实现灵活的抽奖逻辑
award 表通过“奖品标识 + 发放配置”组合方式,统一管理各种奖品类型并支持灵活发放逻辑,是抽奖系统中实现奖品抽象与发奖解耦的关键数据结构。
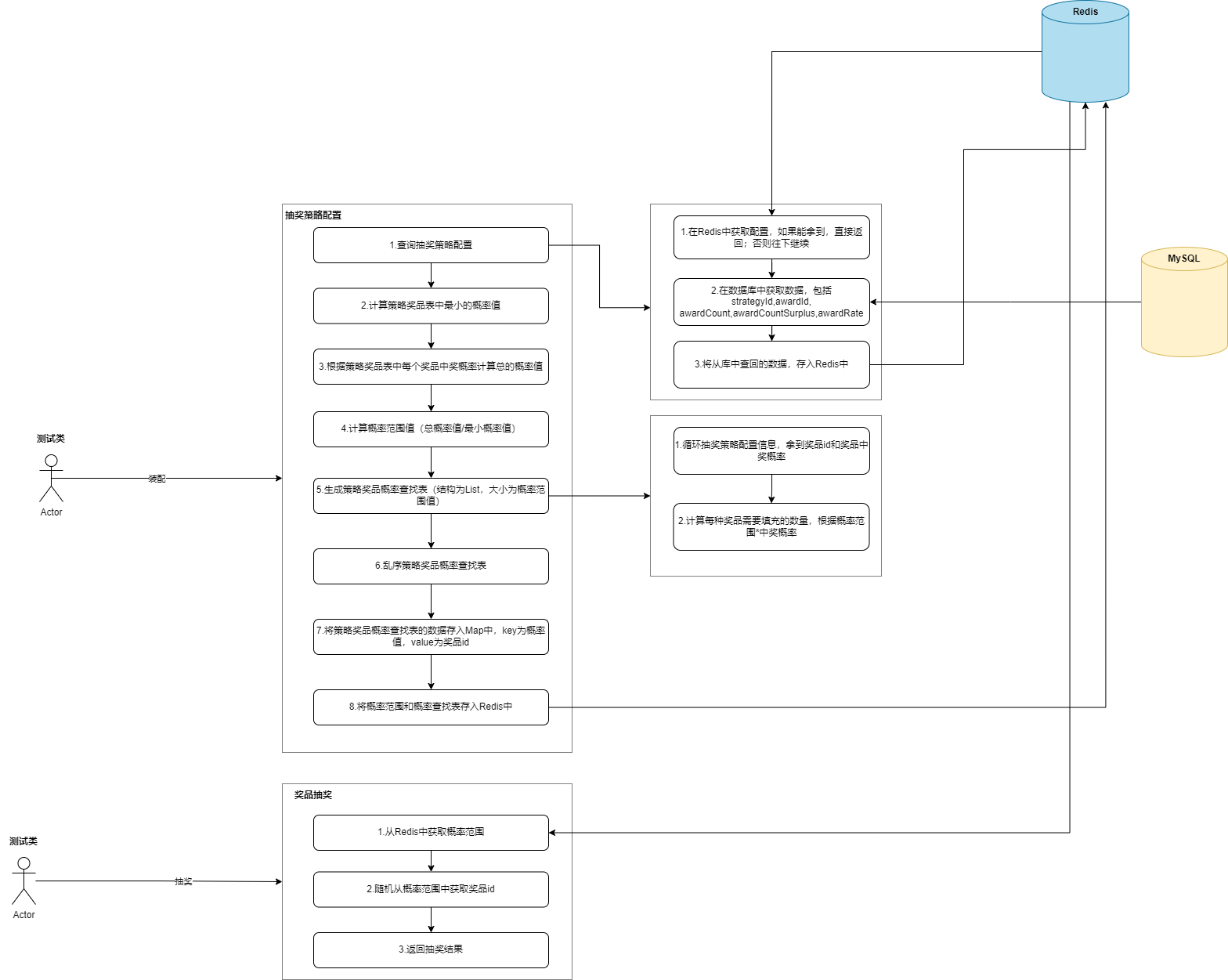
策略概率装配处理
实现了抽奖策略的装配,过程中用到数据库查询、策略值计算、Redis Map 数据存储。
抽奖算法
抽奖的算法一种是空间换时间,另外一种是时间换空间。映射到方案上,空间换时间,是提前计算好抽奖概率分布,用本地内存 guava 或者 redis 存储,最后抽奖的时候通过生成的随机值,在空间内定位即可,复杂度为O(1)。
但要注意,本地内存更快,Redis 相对慢一些。但 Redis 可以直接解决分布式存储问题,本地内存需要让多台分布式机器都保持数据的同步更新,需要引入配置中心以及定时检测的手段,来处理应用启动前/运行中,对活动新增/变更做本地内存做数据加载处理(大厂中一些非常高并发的场景,会申请内存更大的机器来做这样的事情)。
另外一种是时间换空间,就是抽奖的计算,可以抽奖的时候生成一个随机值,之后和概率范围for循环比对。这样的场景适合那种需要非常大的空间存放抽奖概率不划算的时候,可以考虑这种。也可以在程序中设定,当总概率值超过100万,则不存储,而是改为循环比对。但,一切的手段,都要与实际诉求来依赖。
我们项目中实现的是第一种,以空间换时间。存放到Map中,在抽奖时把随机值当索引使用,直接获取对应的奖品。 通过Redis存储策略配置,使得多个应用实例可以共享同一套抽奖策略。通过预先计算好的概率表和直接索引访问,使得抽奖操作的时间复杂度为O(1)。 防止预测 :即使知道概率分布,由于乱序操作,外部也无法预测具体哪个随机数会对应哪个奖品。
策略权重概率装配
实现抽奖系统可以控制多少积分能抽取到哪些奖品的概率范围。
将后续需要用到的权重抽奖规则,进行提前装配处理。拆分成装配接口和调度接口。这样可以保持接口单一职责,避免使用方调用装配操作。装配是活动在创建或者审核的时候初始化的装配动作。 之后在装配接口中重构装配操作,满足对权重策略的装配处理。—— 这里会在实体对象中填充充血方法。
所有装配的数据都会存放到 Redis Map 数据结构下。对于权重的策略装配为策略ID+权重值组合。
最终用户在从装配的工厂中执行抽奖的时候,则可以通过策略ID抽奖和策略ID+权重值组合的方式抽奖
充血对象:StrategyEntity、StrategyRuleEntity, 在权重抽奖的装配中,需要在实体对象中添加对应的方法,这样可以把属于实体的方法和实体聚合,让行为和逻辑在一个对象中。
public class StrategyEntity {
/** 抽奖策略ID */
private Long strategyId;
/** 抽奖策略描述 */
private String strategyDesc;
/** 抽奖规则模型 rule_weight,rule_blacklist */
private String ruleModels;
public String[] ruleModels() {
if (StringUtils.isBlank(ruleModels)) return null;
return ruleModels.split(Constants.SPLIT);
}
public String getRuleWeight() {
String[] ruleModels = this.ruleModels();
for (String ruleModel : ruleModels) {
if ("rule_weight".equals(ruleModel)) return ruleModel;
}
return null;
}
}
public class StrategyRuleEntity {
/** 抽奖策略ID */
private Long strategyId;
/** 抽奖奖品ID【规则类型为策略,则不需要奖品ID】 */
private Integer awardId;
/** 抽象规则类型;1-策略规则、2-奖品规则 */
private Integer ruleType;
/** 抽奖规则类型【rule_random - 随机值计算、rule_lock - 抽奖几次后解锁、rule_luck_award - 幸运奖(兜底奖品)】 */
private String ruleModel;
/** 抽奖规则比值 */
private String ruleValue;
/** 抽奖规则描述 */
private String ruleDesc;
/**
* 获取权重值
* 数据案例;4000:102,103,104,105 5000:102,103,104,105,106,107 6000:102,103,104,105,106,107,108,109
*/
public Map<String, List<Integer>> getRuleWeightValues() {
if (!"rule_weight".equals(ruleModel)) return null;
String[] ruleValueGroups = ruleValue.split(Constants.SPACE);
Map<String, List<Integer>> resultMap = new HashMap<>();
for (String ruleValueGroup : ruleValueGroups) {
// 检查输入是否为空
if (ruleValueGroup == null || ruleValueGroup.isEmpty()) {
return resultMap;
}
// 分割字符串以获取键和值
String[] parts = ruleValueGroup.split(Constants.COLON);
if (parts.length != 2) {
throw new IllegalArgumentException("rule_weight rule_rule invalid input format" + ruleValueGroup);
}
// 解析值
String[] valueStrings = parts[1].split(Constants.SPLIT);
List<Integer> values = new ArrayList<>();
for (String valueString : valueStrings) {
values.add(Integer.parseInt(valueString));
}
// 将键和值放入Map中
resultMap.put(ruleValueGroup, values);
}
return resultMap;
}
}
权重是一种阶梯行为,达到后必中奖,不能这个时候告诉用户无库存了,直接给个兜底积分。所以一般这类的都是发奖的时候写个渠道值,之后运营是提前把这部分预算申请好的。
问题1:黑名单和权重模式直接返回,是不考虑库存不足了么
黑名单直接兜底奖励,权重为必中奖,不能让用户必中奖还走到其他非这个范围的奖品。
问题2:假设我们认为权重是必中奖,那我们怎么保证它的库存一定是充足的呢?在代码中,根据用户的抽奖积分,拿到权重对应的奖品ID列表,这些奖品的库存是存在一定概率为0的,此时没有办法去扣减库存,不就出问题了吗?
权重范围的抽奖,是申请好的预算,不能这个用户都获得了奖品,但最后不给发放。这样会产生客诉。所有进入比如6000积分的,那么最后是运营已经申请好了额外的预算,让用户可以中奖。属于后置计算奖品库存就可以了。
问题3:可是这里对于后台来说,根本就不知道有多少个权重范围内的奖品被抽到,也不知道库存是多少,如果已经被抽完了之后再有人继续抽奖怎么办
- 首先这里有一个目标结果是,权重是必须中奖的,允许说权重了还没有库存了,这样的客诉会导致诚信问题,举报的舆情是更大的麻烦。
- 对于权重的抽奖范围值,运营是可以拿到每天以及预计到本周,本月,可能消耗掉的库存数量。之后提前准备好了奖品量。而每日对于权重抽奖的奖品量是可以统计的。
- 此外,有单独记账诉求,也可以设计出单独的奖品比如109 以外的 201、202、203 等这些为权重范围,扣减库存。非权重类的不做展示。这个在以前的设计讨论中是有的,不过最终是选择了更简单的方式,没有使用这样复杂的维护处理。但有是一个方案。
问题4:如果在权重范围内必中奖,那用户超过权重值之后是不是每次都会中奖对应的奖品,这样不会有问题吗
添加“次数校验”节点,记录已中奖次数。
抽奖概率装配中,当概率极低(如万分位)时,“空间换时间”策略可能导致内存溢出(OOM);若将高概率部分(如80%)用 if直接判断返回,低概率部分(20%)用 Redis 存储查找,是否能节省资源? 可以的,redis中已经有一个概率范围,我们在存乱序map搜索表的Key时只存储剩下20%的。而概率范围是包含全部,在生成随机值的时候,查到直接返回,查不到就代表属于最大概率那部分,返回最大概率奖品即可
抽奖前置规则过滤
用户执行抽奖时会判断是否已经超过N积分,如果超过N积分则可以在限定范围内进行抽奖。同时如果用户是黑名单范围的羊毛党用户,则只返回固定的奖品ID。
通过工厂和策略定义出规则模型,再通过模板模式定义出抽奖的基本流程,来使用抽奖规则。
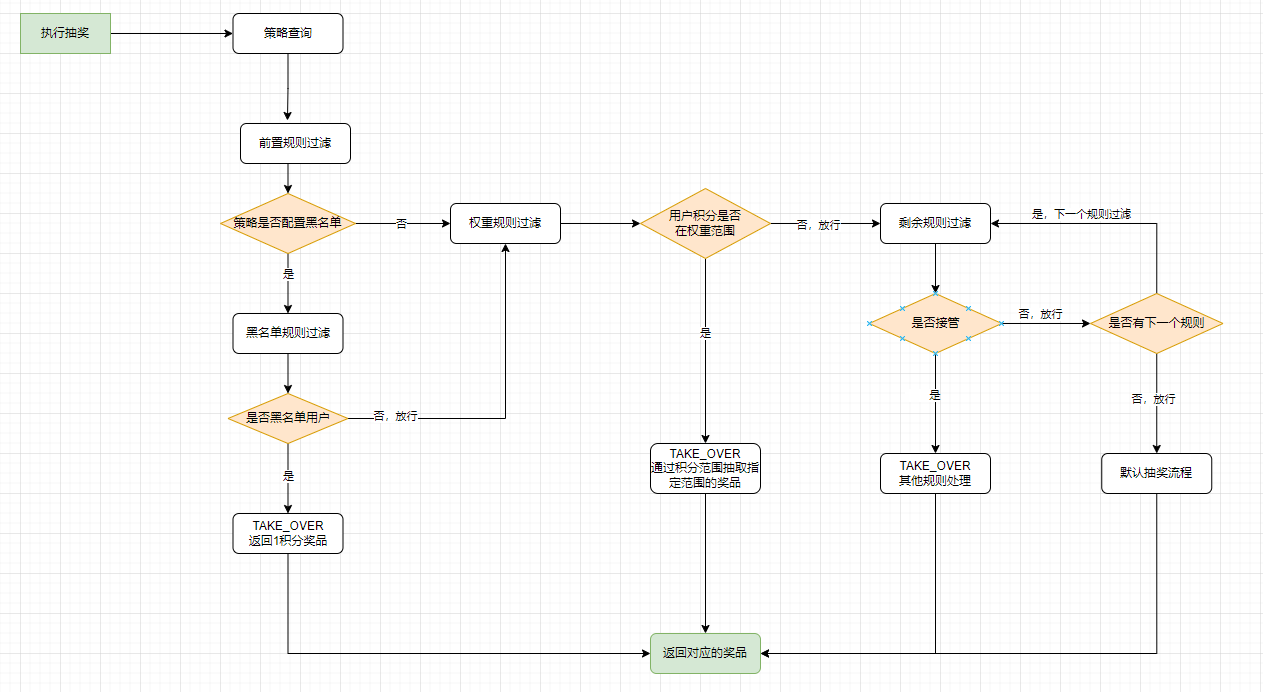 通过 DefaultLogicFactory的 openLogicFilter方法获取所有可用的逻辑过滤器,返回一个映射(Map)logicFilterGroup:
通过 DefaultLogicFactory的 openLogicFilter方法获取所有可用的逻辑过滤器,返回一个映射(Map)logicFilterGroup:
- 键(Key):规则模型(如 RULE_BLACKLIST、RULE_WIGHT的字符串表示)。
- 值(Value):对应的规则过滤器(ILogicFilter实例,如 RuleBackListLogicFilter、RuleWeightLogicFilter)。
先处理黑名单规则,仔顺序执行剩余规则的过滤
黑名单规则处理
- 从 logics参数中过滤出包含黑名单规则代码(如 RULE_BLACKLIST)的规则,并取第一个匹配项(findFirst)。
- 若存在黑名单规则,通过 logicFilterGroup获取对应的黑名单过滤器(ILogicFilter)。
- 构建 RuleMatterEntity(规则上下文实体),设置用户ID、策略ID、规则模型等参数。
- 调用黑名单过滤器的 filter方法执行校验: 若结果不是 ALLOW(允许),说明用户被黑名单拦截,直接返回该结果。
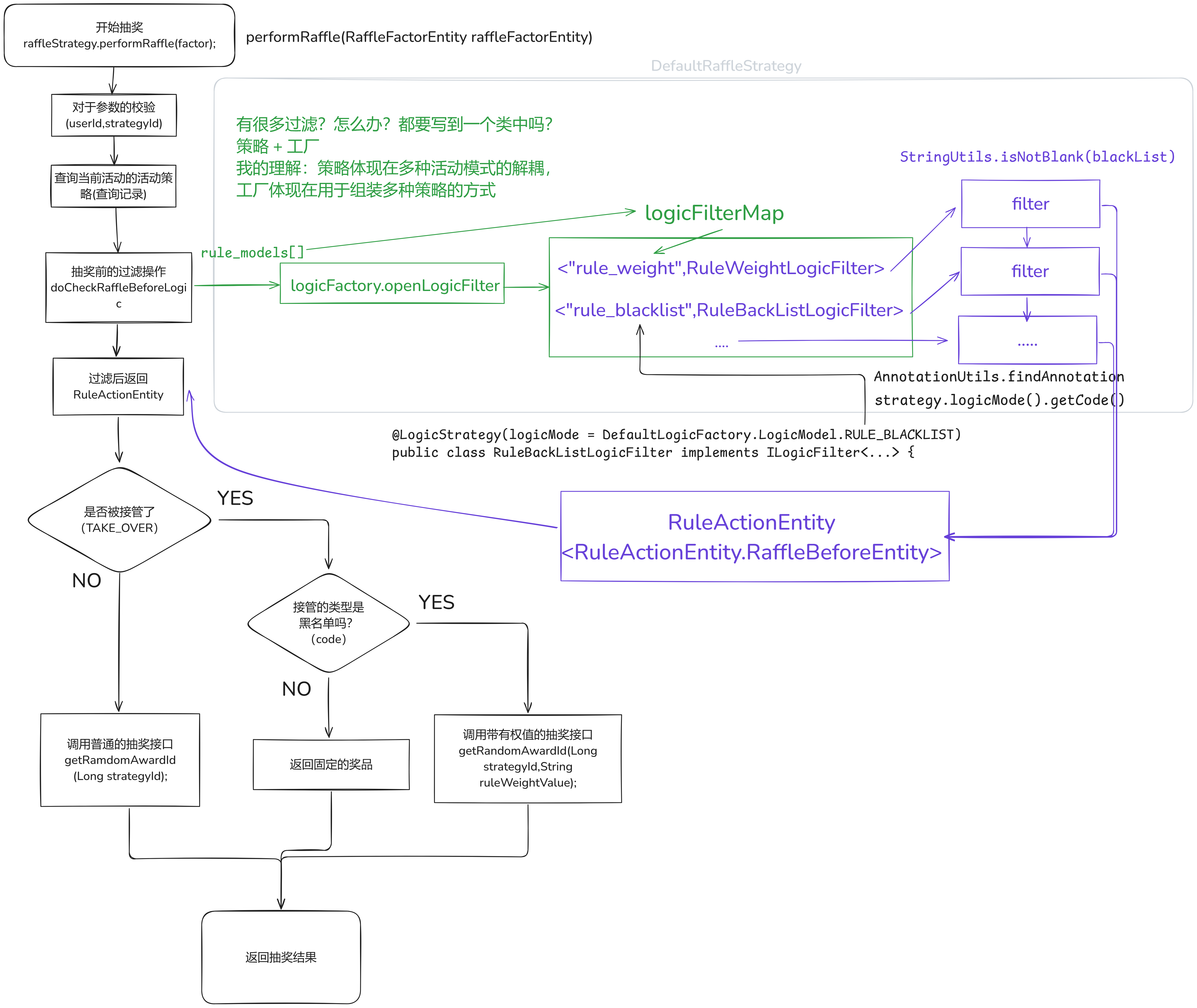 抽奖前有很多的规则过滤,不需要写到一个类中(代码臃肿,耦合度高),而是通过工厂+策略的方式。策略体现在多种活动模式的解耦(过滤规则等)。工厂用于组装多种策略模式。
抽奖前有很多的规则过滤,不需要写到一个类中(代码臃肿,耦合度高),而是通过工厂+策略的方式。策略体现在多种活动模式的解耦(过滤规则等)。工厂用于组装多种策略模式。
什么时候需要定义Entity:一般在确定是5个字段以内,内部自己的流转不对外的方法。如果是 http、rpc 这类对外的接口,一般用对象。避免后续调整,外部也跟着动。
抽奖中置规则过滤
本节扩展「次数过滤」,这个规则的作用是为任何一个奖品配置抽奖抽奖n次后解锁的操作。创建了抽奖次数限制规则过滤器(RuleLockLogicFilter),将用户抽奖次数与规则限制次数比对。
增加了查询抽奖中得到了某个奖品ID后,进行规则的过滤。 这个规则会直接影响用户是否会中该奖品。如果被拦截管控,则会打印临时日志。后续将执行抽奖后规则 rule_luck_award 走兜底奖励。
主要判断规则抽奖奖品的限制规则和用户的抽奖次数,当次数超过规则限定值后,则发放该奖品,否则进行拦截。拦截后,后续则进行抽奖后置规则处理,返回兜底类奖品。其实这样就是扩展了积分中奖概率 这个 userRaffleCount 值,我们可以在测试过程中通过反射进行进行mock值,来进行不同流程的验证。比如把 userRaffleCount 通过 ReflectionTestUtils.setField(ruleLockLogicFilter, "userRaffleCount", 0L); 设置0、10、100 都是可以的,这样就可以验证不同的流程了。
抽奖中规则过滤
- 通过 repository查询当前策略(strategyId)和奖品ID(awardId)对应的“抽奖中规则模型列表”(raffleCenterRuleModelList),可能包含库存检查、用户限制等规则。
- 调用 doCheckRaffleCenterLogic方法,传入用户ID、策略ID、奖品ID及抽奖中规则模型,判断是否触发拦截。
- 触发拦截就走兜底奖励,否则返回最终奖品ID
空指针异常:注意每次测试时要清除redis中的数据,否则上一部分的测试数据会对本部分造成影响。
责任链模式处理抽奖规则
通过责任链抽象原有的抽奖前规则,顺序的将责任节点通过责任链工厂,从库中读取的责任节点进行顺序填充到责任链上。 这样的工厂方式可以更好的根据不同的策略创建出所需的责任链。属于责任链+工厂的组合编写方式
责任链核心组件
- ILogicChainArmory :责任链装配接口,定义了链节点的连接方法
- ILogicChain :责任链接口,继承自ILogicChainArmory,定义了规则逻辑处理方法
- AbstractLogicChain :抽象责任链,实现了ILogicChain接口的基本功能
- 具体责任链实现 :如DefaultLogicChain(默认规则)、BlackListLogicChain(黑名单规则)、RuleWeightLogicChain(权重规则)
- DefaultChainFactory :责任链工厂,负责创建和管理责任链
1. 节点的动态添加
责任链的节点是通过配置动态添加的,主要通过以下方式实现:
- 数据库配置 :在策略表中通过 ruleModels 字段配置责任链节点,如 rule_blacklist 、 rule_weight 等
- 工厂方法动态构建 :在 DefaultChainFactory.openLogicChain() 方法中,根据策略配置动态构建责任链
// 按照配置顺序装填用户配置的责任链
ILogicChain logicChain = applicationContext.getBean(ruleModels[0], ILogicChain.class);
ILogicChain current = logicChain;
for (int i = 1; i < ruleModels.length; i++) {
ILogicChain nextChain = applicationContext.getBean(ruleModels[i], ILogicChain.class);
current = current.appendNext(nextChain);
}
// 责任链的最后装填默认责任链
current.appendNext(applicationContext.getBean(LogicModel.RULE_DEFAULT.getCode(), ILogicChain.class));
原型模式 :使用Spring的原型模式( @Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE) )创建责任链节点,确保每次获取的都是新实例,避免状态共享问题
2. 节点的删除
节点的删除主要通过以下方式实现:
- 配置修改 :修改策略表中的 ruleModels 字段,移除不需要的节点
- 缓存更新 :系统使用 ConcurrentHashMap 缓存责任链,当配置变更时,需要清除缓存或更新缓存
// 存放策略链,策略ID -> 责任链
private final Map<Long, ILogicChain> strategyChainGroup = new ConcurrentHashMap<>();
责任链的终止有两种情况:
- 规则接管 :当某个责任链节点决定接管处理流程时,会直接返回结果,不再传递给下一个节点,例如黑名单过滤、权重抽奖等
- 如果所有规则节点都不接管,最终会到达默认节点(DefaultLogicChain),该节点没有下一个节点,链在此终止
使用 ConcurrentHashMap 缓存已构建的责任链,避免重复构建;责任链节点实现了快速失败机制,当条件不满足时立即返回,不再执行后续逻辑;使用Spring的原型模式创建责任链节点,避免状态共享导致的性能问题;
在调用抽奖的时候为每个调用创建一个对应的责任链,可以动态的添加策略的责任节点。活动唯一编号通过策略id表现,只要是唯一id即可。
通过构造函数注入所有实现了的责任链节点 Map<String, ILogicChain> logicChainGroup String 存放的是对象的 bean 名称。 openLogicChain 方法,通过策略id,查询到配置的规则列表,在通过规则列表填充责任链节点数据。最后使用时调用即可。
责任链中各个节点的传递是依靠next().logic(userId, strategyId)方法来实现,因此各个节点的入参都是userId和strategyId
抽奖规则树模型结构设计
抽奖中到抽奖后的规则,它是一个非多分支情况的规则过滤。单独的责任链是不能满足的,如果是拆分开抽奖中规则和抽奖后规则分阶段处理,中间单独写逻辑处理库存操作 。那么是可以实现的。但这样的方式始终不够优雅,配置化的内容较低,后续的规则开发仍需要在代码上改造。 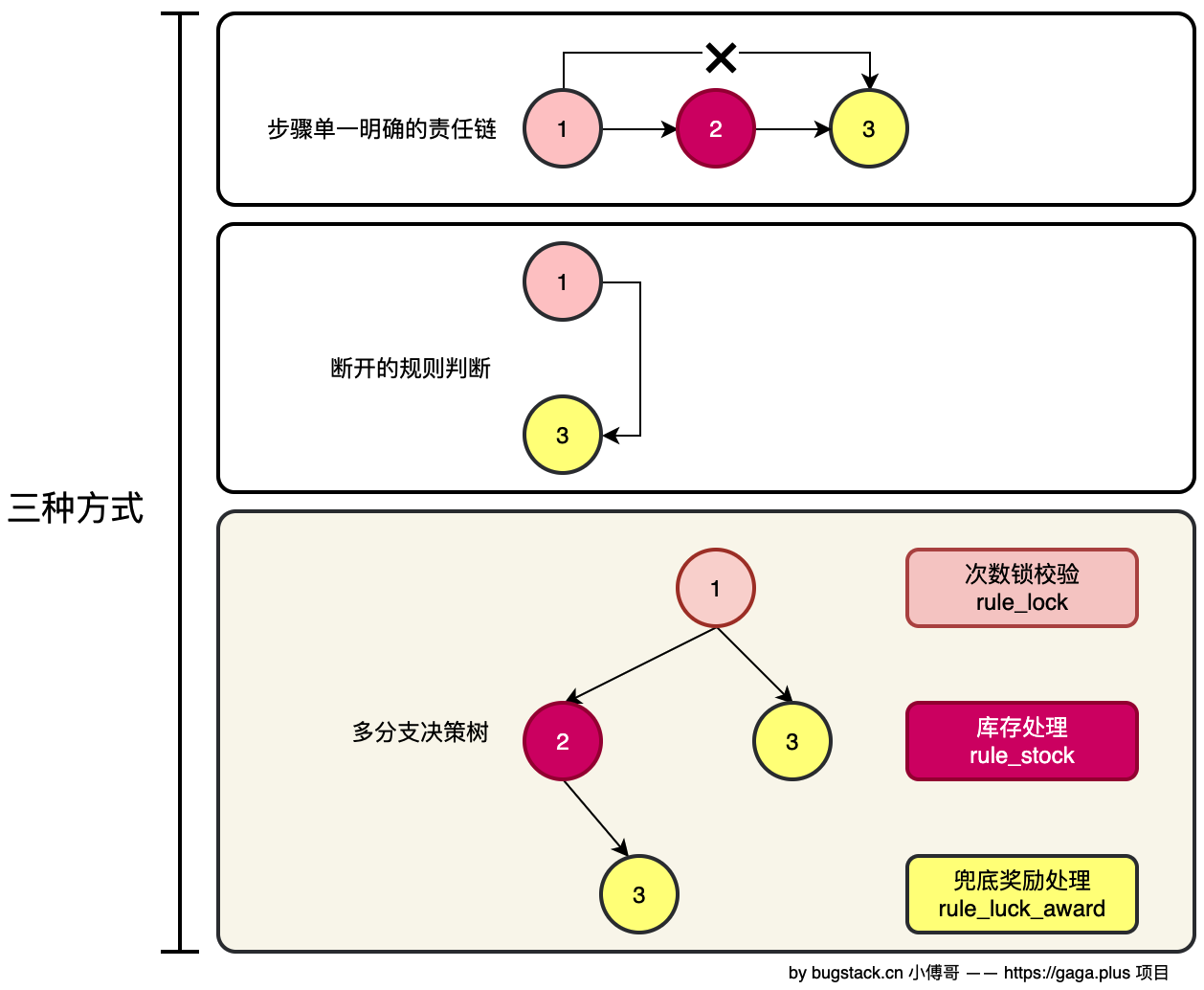 引入新的设计模式结构,解决先阶段中抽奖策略规则的中、后两部分执行问题。通过组合模式的规则引擎,让过滤节点可以满足一颗二叉树的结构,自由的组合和多分支链路的方式完成流程的处理。
引入新的设计模式结构,解决先阶段中抽奖策略规则的中、后两部分执行问题。通过组合模式的规则引擎,让过滤节点可以满足一颗二叉树的结构,自由的组合和多分支链路的方式完成流程的处理。
规则树在系统中通过三张核心表进行存储:
- rule_tree表 :存储规则树的基本信息
- tree_id :规则树唯一标识
- tree_name :规则树名称
- tree_desc :规则树描述
- tree_node_rule_key :规则树根节点的规则键
- rule_tree_node表 :存储规则树的节点信息
- tree_id :关联规则树ID
- rule_key :节点规则键(如 rule_lock 、 rule_stock 、 rule_luck_award )
- rule_desc :节点规则描述
- rule_value :节点规则值(如锁定次数、兜底奖品ID等)
- rule_tree_node_line表 :存储节点间的连线关系
- tree_id :关联规则树ID
- rule_node_from :起始节点规则键
- rule_node_to :目标节点规则键
- rule_limit_type :限定类型(如 EQUAL 、 GT 等比较操作符)
- rule_limit_value :限定值(如 ALLOW 、 TAKE_OVER 等结果类型)
规则树模型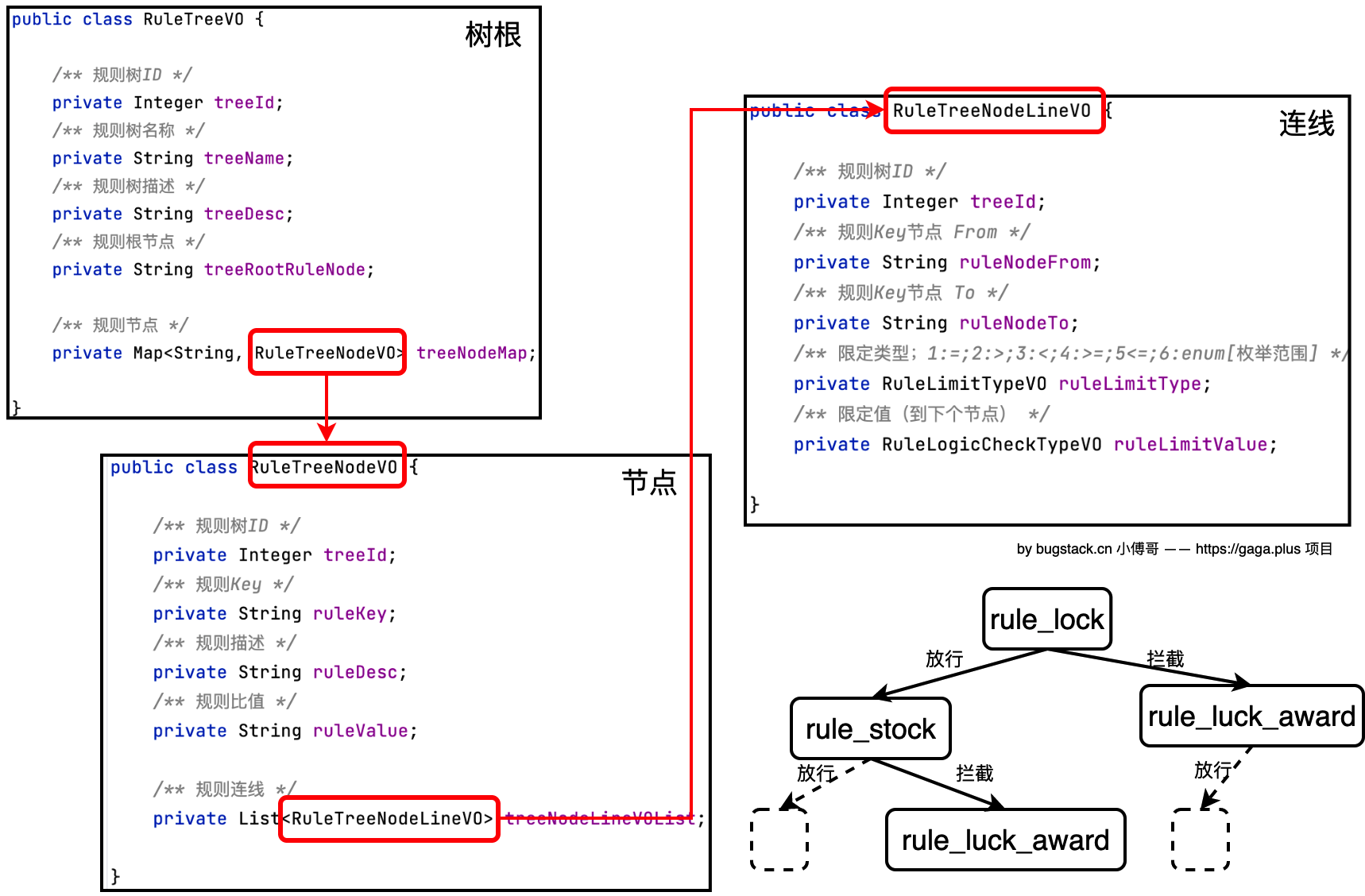
- RuleTreeVO 决策树的树根信息,标记出最开始从哪个节点执行「treeRootRuleNode」。
- RuleTreeNodeVO 决策树的节点,这些节点可以组合出任意需要的规则树。
- RuleTreeNodeLineVO 决策树节点连线,用于标识出怎么从一个节点到下一个节点。
规则树采用决策树模式实现,主要通过以下组件协同工作:
- DecisionTreeEngine :决策树引擎,负责规则树的执行流程。可以让使得工厂类更加专注于创建对象和组织对象之间的关系,而不涉及具体的业务逻辑
- 从根节点开始,按照节点间的连线关系遍历执行
- 根据每个节点的执行结果( ALLOW / TAKE_OVER )决定下一个节点
- 当没有下一个节点或遇到 TAKE_OVER 结果时,返回最终结果
- 核心方法
- nextNode方法:
- 接受两个参数:matterValue 是当前节点的规则值,treeNodeLineVOList 是当前节点的所有可能的后继节点。
- 首先检查 treeNodeLineVOList 是否为空,如果为空则直接返回 null,表示没有可执行的后继节点。
- 然后通过循环遍历 treeNodeLineVOList 中的每个节点线条,对于每个节点线条,调用 decisionLogic 方法来判断是否满足执行条件,如果满足条件,则返回该节点的ID。
- 如果循环结束后仍未找到可执行的节点,则抛出一个运行时异常,表示计算失败,未找到可执行节点。
- decisionLogic方法:
- 接受两个参数:matterValue 是当前节点的规则值,nodeLine 是当前节点的一条可能的后继节点线条。
- 根据 nodeLine 中的规则限定类型来判断给定的规则值是否满足条件。
- 如果给定的规则值满足条件,则返回 true,表示可以执行该后继节点。
- nextNode方法:
- ILogicTreeNode接口 :规则节点标准接口
- 定义了 logic 方法,接收用户ID、策略ID、奖品ID等参数
- 返回 TreeActionEntity ,包含执行结果和可能的奖品信息
- 具体节点实现,使用接口加实现类的创建方法:
- RuleLockLogicTreeNode :次数锁节点,检查用户抽奖次数是否达到解锁条件
- RuleStockLogicTreeNode :库存节点,处理奖品库存扣减逻辑
- RuleLuckAwardLogicTreeNode :兜底奖品节点,提供默认奖品
- DefaultTreeFactory :规则树工厂,负责创建决策树引擎,将节点和树组装起来
- 通过Spring的依赖注入收集所有 ILogicTreeNode 实现
- 根据规则树配置创建 DecisionTreeEngine 实例
系统支持规则的动态组合和热更新,主要通过以下机制实现:
- 数据库配置与缓存结合
- 规则树的所有配置存储在数据库中,支持通过后台修改
- 使用Redis缓存规则树配置,提高访问效率
- 在 StrategyRepository.queryRuleTreeVOByTreeId 方法中实现了缓存与数据库的协同
- 缓存更新机制 :
- 优先从缓存获取规则树配置( redisService.getValue(cacheKey) )
- 缓存未命中时,从数据库加载并重建缓存
- 规则树修改后,可以通过清除缓存触发重新加载
- 规则树的动态组装 :
- 从数据库加载规则树、节点和连线数据
- 将节点连线转换为Map结构,便于快速查找和遍历
- 构建完整的 RuleTreeVO 对象,包含树的基本信息和节点关系
- 规则热更新支持 :
- 修改数据库中的规则配置(如修改 rule_value 调整概率)
- 清除对应的Redis缓存
- 下次访问时自动从数据库重新加载最新配置
系统支持运营人员通过后台动态调整规则,主要包括:
- 概率调整 :
- 修改 rule_tree_node 表中的 rule_value 字段
- 例如调整 rule_lock 节点的值,改变解锁所需的抽奖次数
- 或修改 rule_luck_award 节点的值,调整兜底奖品
- 规则流程调整 :
- 修改 rule_tree_node_line 表中的连线关系
- 调整节点间的执行顺序和条件
- 增加或删除节点,实现更复杂的规则逻辑
- 热更新机制 :
- 数据库修改后,清除对应的Redis缓存
- 系统会在下次访问时自动加载最新配置
- 无需重启服务,实现规则的实时更新
模板模式串联抽奖规则
通过模板模式,把规则树的结构设计,整合到抽奖过程中。这样整个抽奖策略过程会包括;责任链进行抽奖计算,基于抽奖计算结果对基础抽奖在进行规则树的过滤,最终返回抽奖结果。 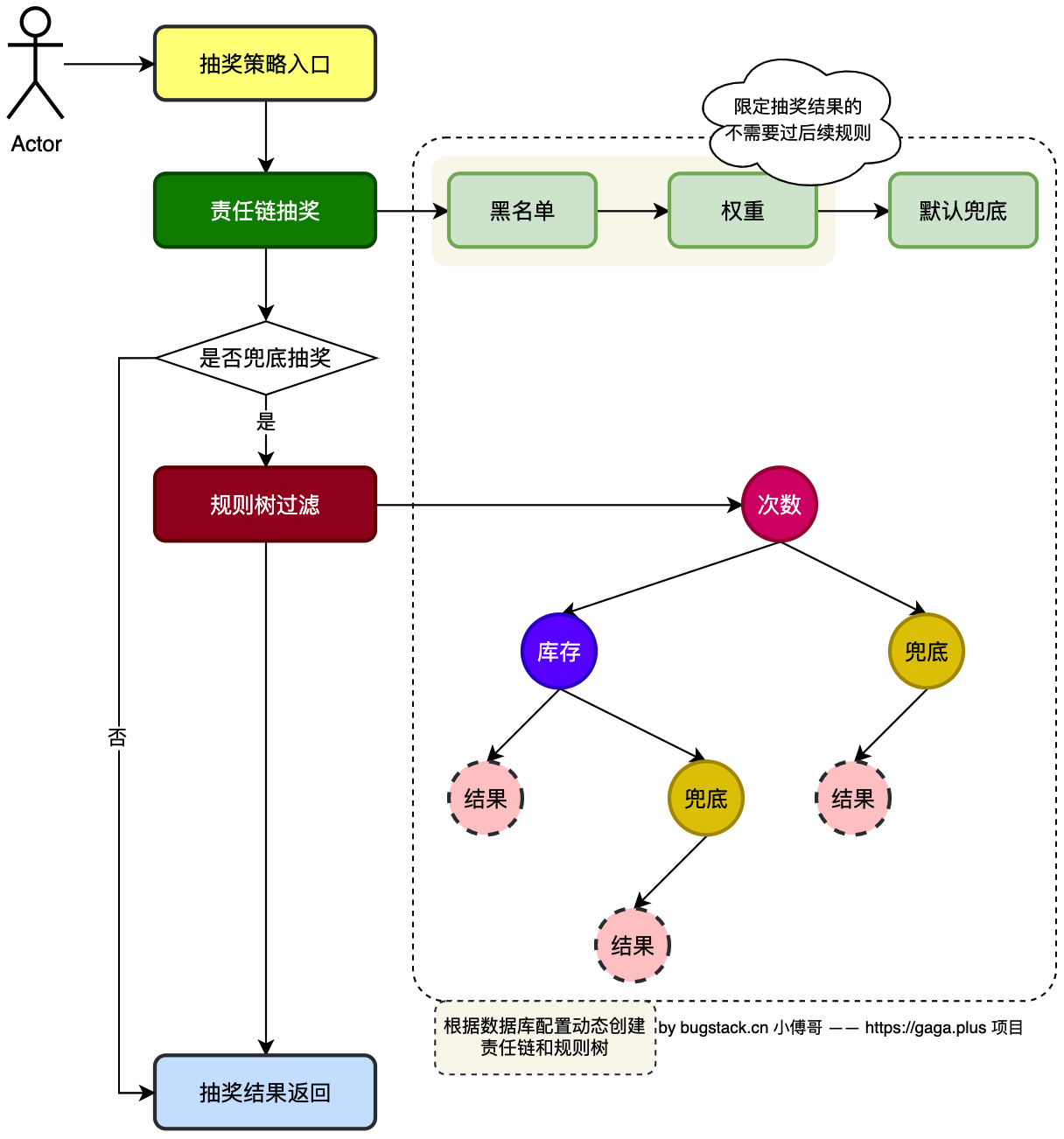 左侧的业务流程,可以通过抽象类定义出调用顺序,右侧的具体操作可以放到实现了抽象类的子类来做具体实现。通过这样的方式,我们在后续看代码的时候,也能直接通过抽象类的模板结构直接知道这块的代码在做什么。而要看细节则进入到每个功能实现里去。
左侧的业务流程,可以通过抽象类定义出调用顺序,右侧的具体操作可以放到实现了抽象类的子类来做具体实现。通过这样的方式,我们在后续看代码的时候,也能直接通过抽象类的模板结构直接知道这块的代码在做什么。而要看细节则进入到每个功能实现里去。
AbstractRaffleStrategy 抽象类:通过模板模式定义出抽奖的标准过程,分为:参数校验、责任链抽奖计算、规则树抽奖过滤、返回抽奖结果。确保所有抽奖策略都遵循相同的步骤。同时定义出所需的抽象方法,让子类来做具体实现。
在子类DefaultRaffleStrategy中调用了责任链的调用、规则树的过滤。这部分代码原来是在抽象类中做的处理,现在迁移出来交给子类,让抽象类模板更多的注重流程的定义和流程节点转换过程的处理。
问题1: 在抽奖系统这里,一个抽奖抽象类只有一个实现类,这样也可以称为模板模式吗?删除抽象类,就保留一个实现类会不会更简洁呢?
除了模板模式的骨架设计,实际抽奖逻辑(如责任链和规则树)被设计为可插拔的策略,通过不同的策略(如责任链策略、规则树策略)来实现多样化的处理流程。 这种设计更接近于策略模式,而不是单纯的模板模式。模板模式通常是较为固定的骨架,但这里的设计考虑了扩展性和配置化。 通过将责任链和规则树设计为独立模块,可以根据业务需求随时插入新的处理逻辑或替换已有的逻辑。这种灵活性并不是经典模板模式的重点
模板模式是父类中定义了流程以及流程中要用的方法,具体方法是在子类实现的,这样子类就只需要关注业务的具体逻辑实现而不需要考虑方法的调用逻辑。 这里和大营销里的抽奖策略抽象类还是不太一样的,这里只是定义抽奖的标准流程,毕竟要用的抽奖方法太多了,也不可能全塞进这一个类里
不超卖库存规则实现
当通过抽奖策略计算完用户可获得的奖品ID后,接下来就需要对这一条奖品记录进行库存的扣减操作。只有奖品库存扣减成功,才可以获得奖品ID对应的奖品,否则将走到兜底奖品。 还需要对上一节实现的规则树节点;次数锁、兜底奖品,都会完善。
首先对于库存集中扣减类的业务流程,是不能直接用数据库表抗的。
- 并发性问题: 如果多个用户同时尝试从同一批库存中扣减商品数量,可能会导致数据的不一致性和冲突。数据库的并发控制机制可能无法有效处理这种情况,导致数据错误或丢失。
- 数据一致性: 在分布式系统中,如果库存数据分布在多个节点或多个数据库中,保持数据一致性就变得更加复杂。直接使用数据库表可能无法有效地处理数据同步和一致性维护的问题。
比如数据库表有一条记录是库存,如果是通过锁这一条表记录更新库存为10、9、8的话,就会出现大量的用户在应用获得数据库的连接后,等待前一个用户更新完库表记录后释放锁,让下一个用户进入在扣减。 这样随着用户参与量的增加,就会有非常多的用户处于等待状态,而等待的用户是持有数据库的连接的,这个连接资源非常宝贵,你占用了应用中其他的请求就进不来,最终导致一个请求要几分钟才能得到响应。【前台的用户越着急,越疯狂点击,直至越来越卡到崩溃】
所以,对于这样的秒杀场景,我们一般都是使用 redis 缓存来处理库存,它只要不超卖就可以。但也确保一点,不要用一条key加锁和等待释放的方式来处理,这样的效率依然是很低的。所以我们要尽可能的考虑分摊竞争,达到无锁化才是分布式架构设计的核心。 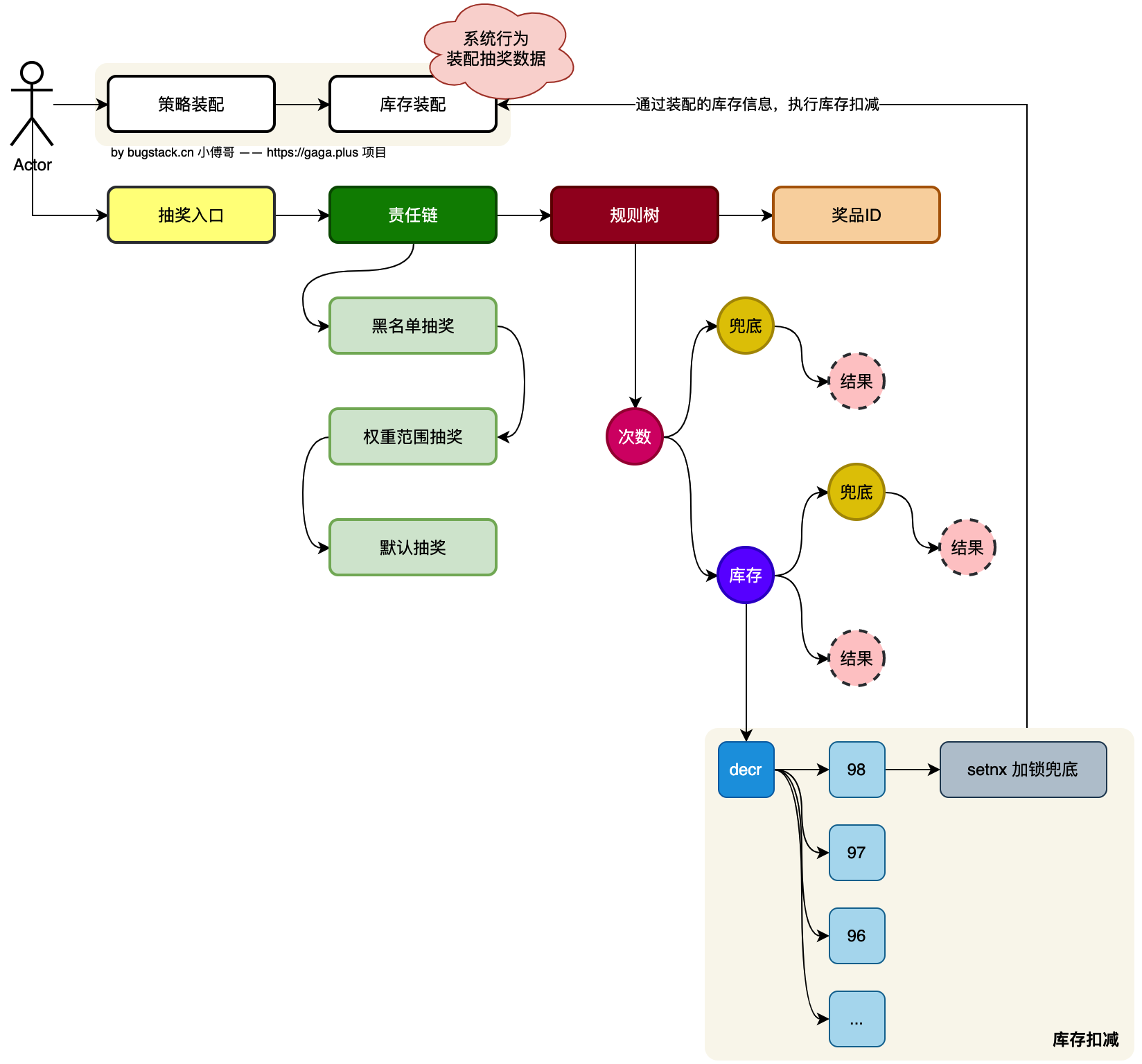
decr + setNx
- 是针对于用户参与的活动库存加锁的,如果是独占锁是针对于活动ID加锁的。滑块锁的核心是去竞态,避免独占影响系统的响应性能。
- 那为什么再加一个锁呢,decr 不就可以。加锁是兜底,你不知道什么时候会出现 decr 不对的情况。如;集群配置问题【特例】、出现redis问题,需要恢复库存。如果没有锁,可能会超卖。
- 在 redis 集群模式下【以我们的场景为例】,decr 请求操作也可能在请求时发生网络抖动超时返回。这个时候decr有可能成功,也有可能失败。可能是请求超时,也可能是请求完的应答超时。 那么decr 的值可能就不准。【实际使用中10万次,可能会有10万零1和不足10万。】例如:A用户执行decr请求的时候成功了,响应的时候,网络发生了抖动,所以实际上A用户扣减成功。那同时B用户执行decr没有发生抖动,这个时候就会超卖。 因为不加锁的话相当于一个库存卖了两次,假设a和b都是最后一次库存时来的,这最后的一个库存成功卖了两次(为什么能成功卖,因为是异步来的)。decr是没有事务性的,并不能保证安全,加了setNx也只是为了兜底而已
- setNx 因为是非独占锁,所以key不存在释放。setNx 的key 可以过期时间可以优化为活动的有效期时间为结束。 ——而独占锁,其实你永远也不好把握释放时间,因为秒杀都是瞬态的,释放的晚了活动用户都走了,释放的早了,流程可能还没处理完。
- 对于 setNx 可能还有些时候,集群主从切换,或者活动出问题的时候恢复。如果恢复的 decr 值多了,那么有 setNx 锁拦截后,会更加可靠。
- 关于库存恢复,一般这类抽奖都是瞬态的,且redis集群非常稳定。所以很少有需要恢复库存,如果需要恢复库存,那么是把失败的秒杀decr对应的值的key,加入到待消费队列中。等整体库存消耗后,开始消耗队列库存。
- 这里的锁的颗粒度在于一个用户一个锁的key,所以没有个人释放再需要被让别人抢占的需要,因为这不是独占锁。所以锁的key可以设置活动结束后释放。
- 不需要恢复,恢复的话是要写入一个队列来消费。但实际基本不需要,因为秒杀都是瞬态的,等补偿恢复,已经基本过去了。所以超卖,快速结束是最好的。
对于非交易的活动类场景,要的就是一个快。快速响应、快速释放,可接受容错失败概率。但不要磨磨唧唧影响我的主核心交易链路。 但凡在618、双11,营销敢超时,就直接下掉。保证用户可下单可支付。否则这黄金时间点,你耽误1分钟都是几个亿的成交额。所以,这类营销秒杀场景下,根本就是保证不超卖,也不恢复库存。
注意:独占锁是加给个人流程的 - 无资源竞争,如贷款单受理。分段/滑块/无锁化,是加给库存的 - 有资源竞争,如秒杀、商品发货等集中资源类。就跟大超时的收银台一样。原来就1个出口,后来一排出口,在后来又有无人化的电子出口。
通过 Redisson 客户端的 decr 方法(底层调用 Redis 的 DECR 命令)实现原子扣减。decr作用是将存储在指定键中的整数值减一,并返回减一后的结果。如果键不存在,那么在执行decr操作时会先将该键的值设置为 0,然后再执行减一操作。
setnx:常用于实现分布式锁的获取操作。通过setnx操作,可以在 redis 中创建一个临时的锁,如果获取锁成功(返回 1),则表示当前客户端获得了锁, 可以执行临界区代码;如果获取锁失败(返回 0),则表示锁已经被其他客户端持有,当前客户端需要等待或者放弃执行临界区代码。
setNx 锁的目的是兜底【setnx 在 redisson 是用 trySet 实现,即redissonClient.getBucket(key).trySet】,比如一开始10,9,8,7已经卖出去了,现在应该从6开始,但是呢,运营不小心把库存又变成10了,这时候来扣减库存会把10扣成9, 但是并没有影响数据库中的实际库存,setNX发现已经有这个key,说明第10个商品已经被卖掉了,这时候返回false,对数据库并不会产生扣减操作, 依次类推,redis中的值能够恢复到6,并且不影响数据库中的库存,这样来兜底,如果是先setNX的话,你判断10有没有锁,有锁的话你就不减少redis中的库存,这样的话,所有用户过来都会是第10个商品,都不能扣减成功, 加setNx锁可以保证不扣减数据库数据的同时还能把redis中的库存变成实际的库存。
因为运营调整的是库存,而不是总数量,所以我们要把每个数字当作是一次发出去的奖品,setNx锁相当于每个已售商品都有"已售"钢印,系统会在真正扣减前会检查“钢印”是否已存在。即使数字被改错,钢印也无法伪造。后续碰到这个数字(重点)先执行 decr,再根据setnx判断的结果作为返回值。 运营调整库存举例:比如活动发布后,奖品A的总库存为200,我们要对奖品A添加100的总库存(补货),就需要重新预热库存缓存(预热的是总库存,不是剩余库存),当我们重新预热数据到缓存的时候(注意:预热的库存是总库存数,不是剩余库存数),库存数从100覆盖到了300, 这时候继续扣减库存的时候,201-300这段我们添加的库存数是没上锁的,可以直接扣减,而0-200 这范围内如果有某库存数上锁了,也就是之前扣减过了,我们就不需要扣减了, 就防止了超卖问题
库存扣减的核心逻辑是在 Redis 完成的,数据库(MySQL)只是备份。 例如: 用户下单 → Redis 扣减库存 → 异步更新数据库。 如果 Redis 扣减成功但数据库更新失败,系统仍以 Redis 为准(避免超卖)。
库存消耗完以后,还需要更新库表的数据量。但这会也不能随着用户消耗奖品库存的速率,对数据库表执行扣减操作。项目采用延迟队列 + 异步更新机制:
- 库存扣减流程 :先扣减 Redis 缓存库存,再将更新消息发送到延迟队列
- 异步更新数据库 : UpdateAwardStockJob 定时任务从队列中获取消息并更新数据库
- 回补机制 :如果 Redis 宕机,可通过数据库初始化 Redis 缓存
问题1:如果进行decr操作之后,但是还没有来得及加锁,redis就挂掉了,那么会不会导致库存遗留问题?这个具体应该怎么解决?
redis 挂了,会是非常大的运维类事故,谁的事故谁负责。之后服务会开启挡板,告知用户暂时下线,后续在开启。刷新后,链接会跳转到其他页面了,不会有抽奖了。而后,redis 修复,数据校验。之后才会上线。如果只是说,加锁的失败了,可以加上监控,但因为是decr 扣减,只要这个值不被增加,是不会超发的。
问题2:超卖和少卖
超卖不会出现,有个保证的点,一个是decr 值的限制,另外一个是对每个key加锁的兜底设计。确保了不会超卖。 少卖是有可能的,核心原因是因为 decr 操作和数据操作不是是一个事务,有可能库存扣减完了,但最终操作库失败了。那么这个库存就丢失了,可能会少卖。 但一般并不会对少卖做过多的流程,如果想管理,也可以把少卖的库存异常,加入单独的 redis 队列来重新消费就可以了。
问题3:在使用延迟队列 + 异步更新数据库时,有没有可能在从队列中poll()出消息之后,还未来得及执行MySQL更新,此时如果程序因为种种原因宕掉,那么就会出现数据不一致。我觉得这里是不是使用redis的stream实现的消息队列进行异步更新
Redis Stream的优势 :
- 消息持久化 :Stream中的消息会被持久化到磁盘,即使Redis重启也不会丢失
- 消息确认机制 :支持XACK命令,只有明确确认后消息才会被标记为已处理
- 消费者组功能 :支持多个消费者协同工作,避免消息重复处理
- 消息重试 :未确认的消息可以重新被消费,解决了程序崩溃导致的消息丢失问题
- 消息ID自动生成 :确保消息的唯一性和有序性
进行如下修改:
- 修改生产者代码,使用 XADD 命令发送消息到Stream
- 改造消费者逻辑,使用消费者组模式( XREADGROUP )读取消息
- 实现消息确认机制,在数据库更新成功后调用 XACK 确认消息
- 设置适当的消息保留策略和消费者组配置
问题4:为什么定时任务每次只取poll的一条数据,由于定时任务5s才执行一次,这样不是会导致队列积压吗,在高并发场景下是不是应该记录某一奖品的消耗总数,一次性进行更新
可以按需调整,具体可以实际的数据量。也可以按照定时更新redis数据量方案,即做任务扫描redis中剩余缓存量定时更新。
如果做库存调整,可以使用decr 与总量对比的方式增加库存。
延迟队列,库存消耗没了以后主动更新库,以及最后活动结束后,可以任务扫描数据更新库存。
对于主从切换导致数据未同步,也就是发生主从切换时,没有同步decr锁,那么这时的setNx也就不起作用了,对于这种情况还需要另做数据核准
前端页面
采用 React 技术开发前端页面。通过 Mock 接口的方式与前端的抽奖页面进行接口对接,完成抽奖的奖品查询和随机抽奖动作。
trigger 模块,专门用于提供触发操作。这里我们把 HTTP 调用、RPC(Dubbo)调用、定时任务、MQ监听等动作,都称为触发操作。触发表示通过一种调用方式,调用到领域的服务上。
在大营销系统中,会提供 HTTP 接口,也会在后续提供 RPC 接口。 RPC 就像 Dubbo 这样的框架,它的调用方式是需要对外提供接口描述性Jar,调用方拿到 Jar 包,就像本地调用接口一样,使用 RPC 框架,远程的调用到你的服务上。 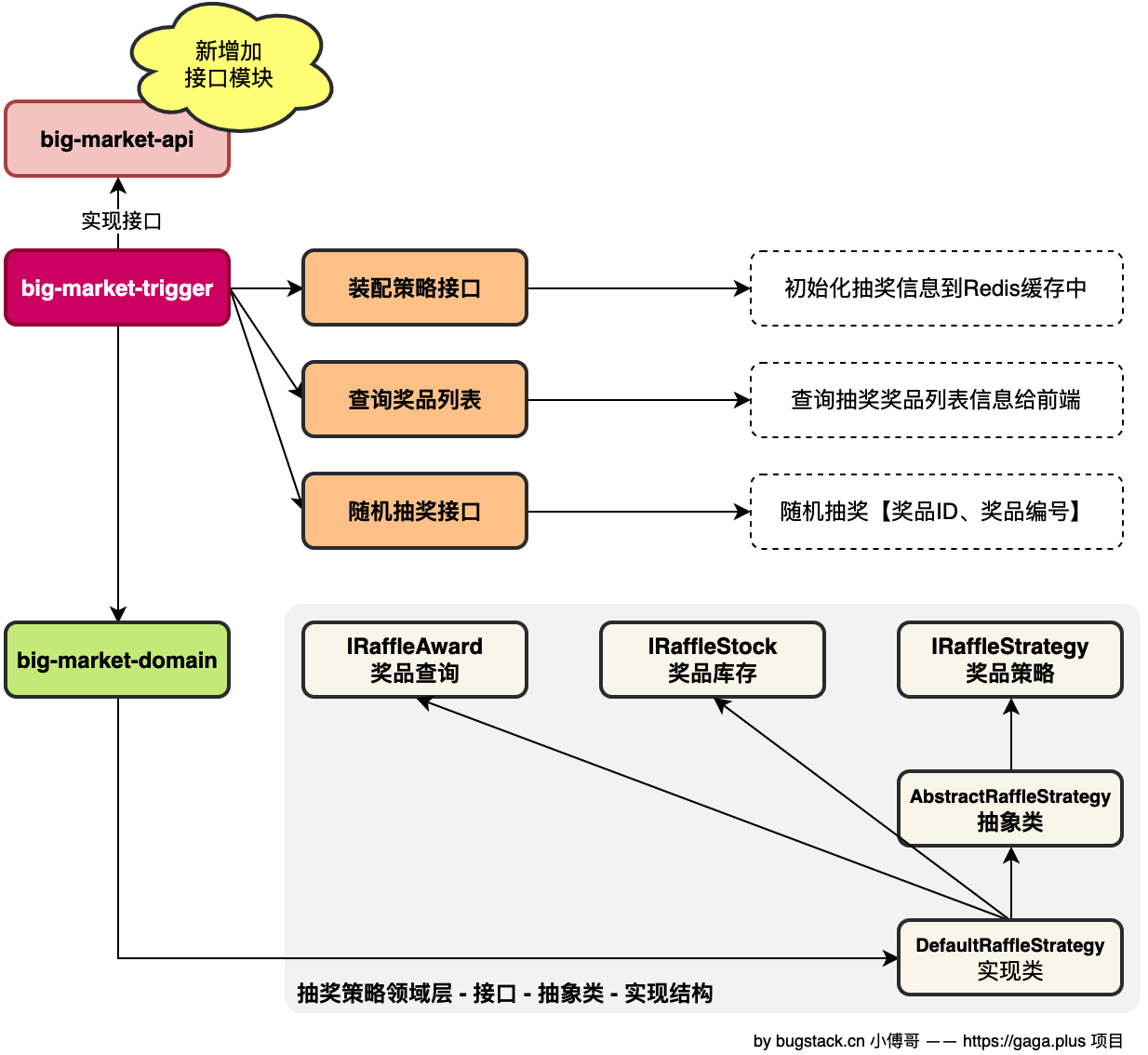
项目部署
将项目创建镜像到Docker中时,注意网络问题,不要使用VPN,
如果推送到Docker Hub不成功,可以考虑更改合适的镜像,然后尝试拉取一个镜像以测试网络连接
docker pull alpine
如果拉取成功且速度较快,说明加速器配置正确。接着再推送镜像。我第一次推送成功镜像是开了VPN才能登进去Docker Hub。大部分的网络问题基本都是由于镜像引起的,因此可以重新设置镜像试试看 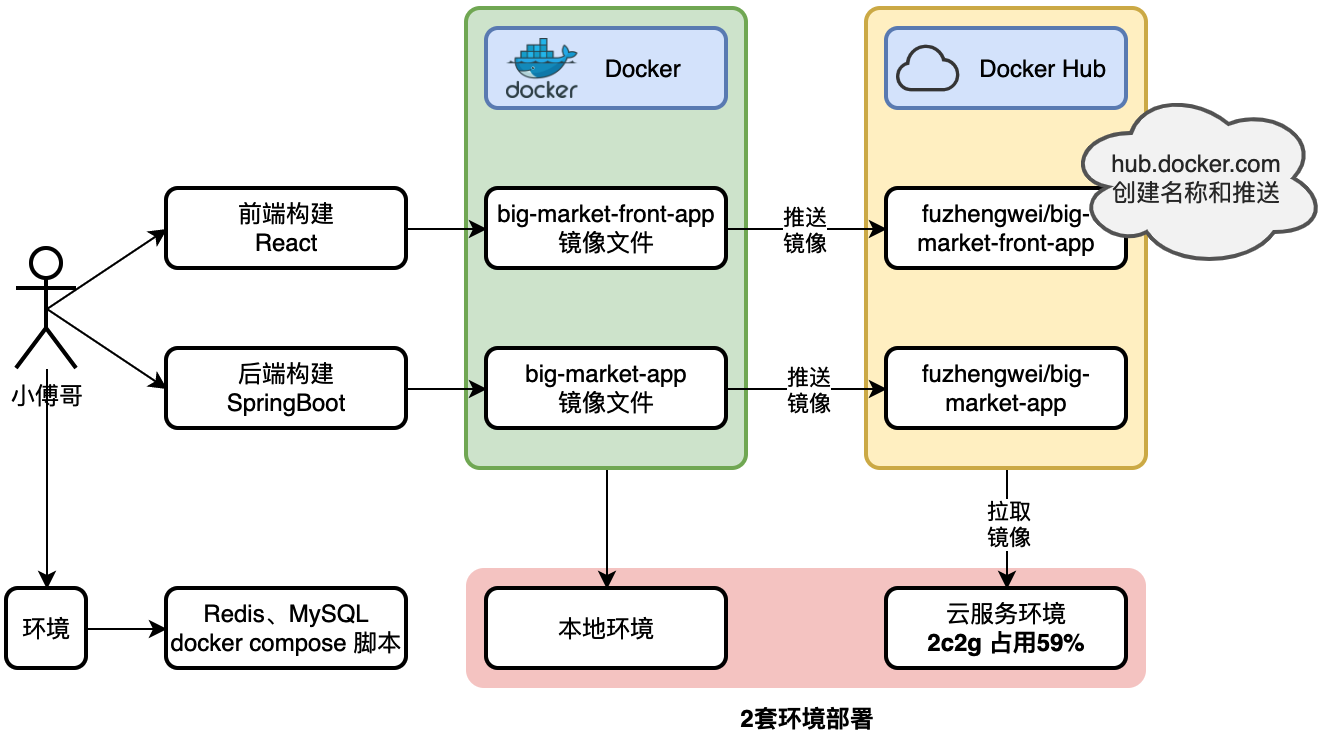 部署流程就是:先创建Docker镜像,再把镜像推送到Docker Hub,然后在把dev-ops的文件复制到云服务器上(记得调整app和front的版本,如1.1->1.2),最后执行部署。 部署策略:本地建库 + 本地开发测试 + 云端部署
部署流程就是:先创建Docker镜像,再把镜像推送到Docker Hub,然后在把dev-ops的文件复制到云服务器上(记得调整app和front的版本,如1.1->1.2),最后执行部署。 部署策略:本地建库 + 本地开发测试 + 云端部署
【本地项目】
|
|——连接——> 本地 Docker 中的 MySQL / Redis
↓ 开发完成,推送代码到云服务器
【云服务器项目】
|
|——连接——> 云服务器 Docker 中的 MySQL / Redis
因此本地数据库的修改并不会影响到云端数据库的数据。所以每完成一阶段都需要进行项目部署。 如果想要把数据直接放在云服务器上,即直接连接云服务器上的数据库,需要把组件的IP地址由本地IP:127.0.0.1改为云服务器IP。 记得在云服务器开放相关组件的端口
组件端口的区别例如MYSQL有13306:3306,如果走外网,那么端口就配置13306,如果是内部连接,端口配置就为3306.
注意
如果在application-dev中修改配置,那么application中必须是dev或者prod进行同步修改。
如果遇到端口重提问题可以通过以下命令解决
# 查看系统保留端口
netsh int ipv4 show excludedportrange protocol=tcp
# 如果 5672 在保留范围内,禁用动态端口范围
netsh int ipv4 set dynamic tcp start=49152 num=16384
# 重启计算机
压测视频:https://www.bilibili.com/video/BV1NA4m1F7iJ