幸运营销汇-开发日志-第三阶段
用户积分需求设计
分析系统中积分的链路,哪里是添加积分,哪里可以消耗积分。以积分作为媒介增加用户的营销活动体验。用户可以知道自己有多少积分,以及在每次完成指定的行为动作后,可以获得积分。
- 抽奖中有随机积分,抽中后可以给用户增加积分。注意黑名单一般会发放一个指定范围的很小的积分值。
- 用户行为动作返利,当用户在抽奖系统中日历📅签到,以及提供出让外部对接的接口,也可以给用户增加积分。
- 最后就是积分消耗,目前这里的积分消耗主要是兑换抽奖资格,也就是和活动 sku 进行兑换。这部分会产生订单。
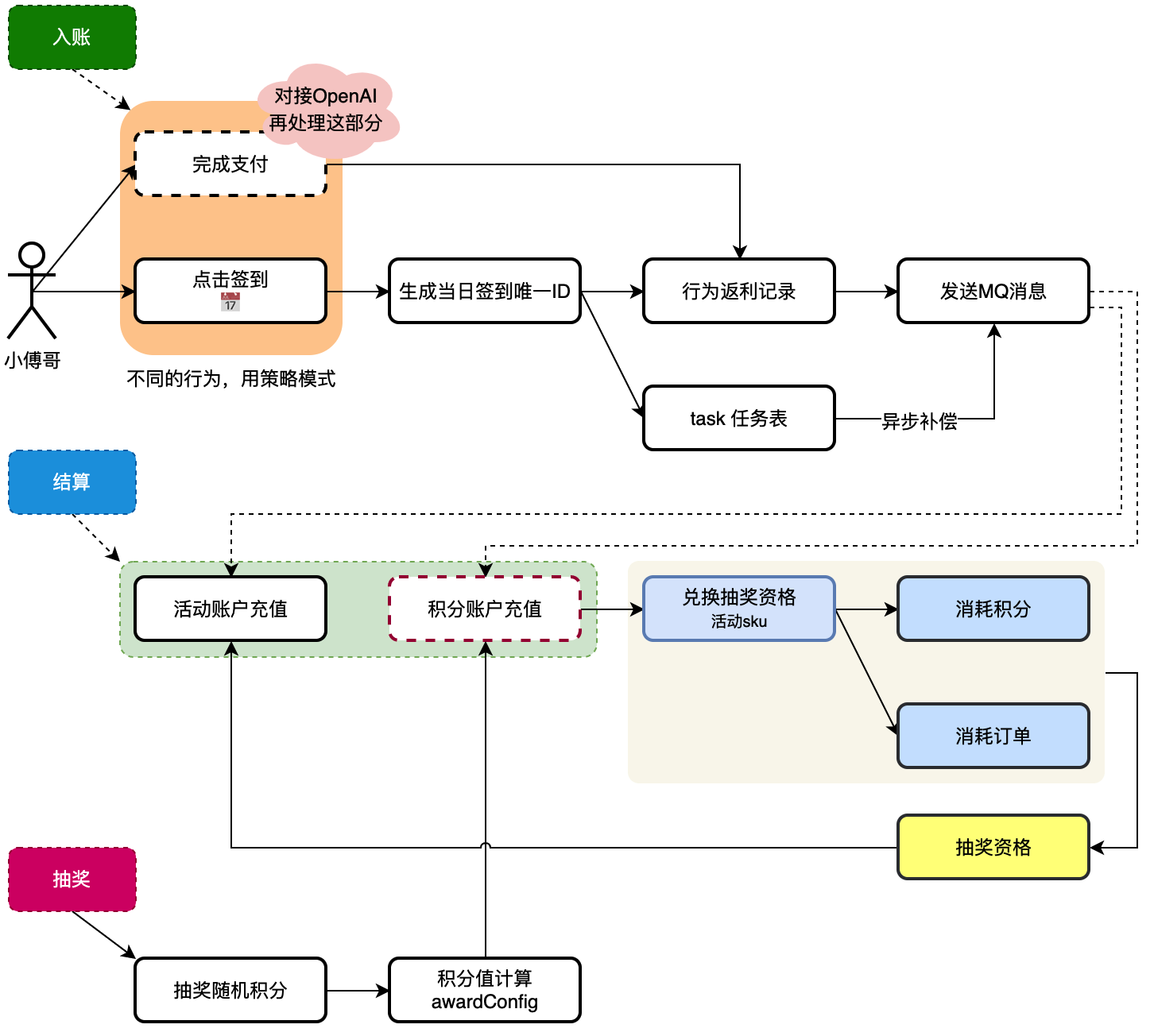
- 首先,入账和结算这里的活动账户是用户可抽奖的活动次数。积分账户是用户整个营销中的积分值。积分值作为媒介可以兑换其他内容,如抽奖的次数。
- 之后,整个过程中会有行为返利增加积分和抽奖增加积分。
- 另外,就是对积分的消耗,消耗积分也会产生积分消耗订单,这样可以确保幂等性。最终消耗积分也就兑换成了抽奖次数.
设计一张积分表 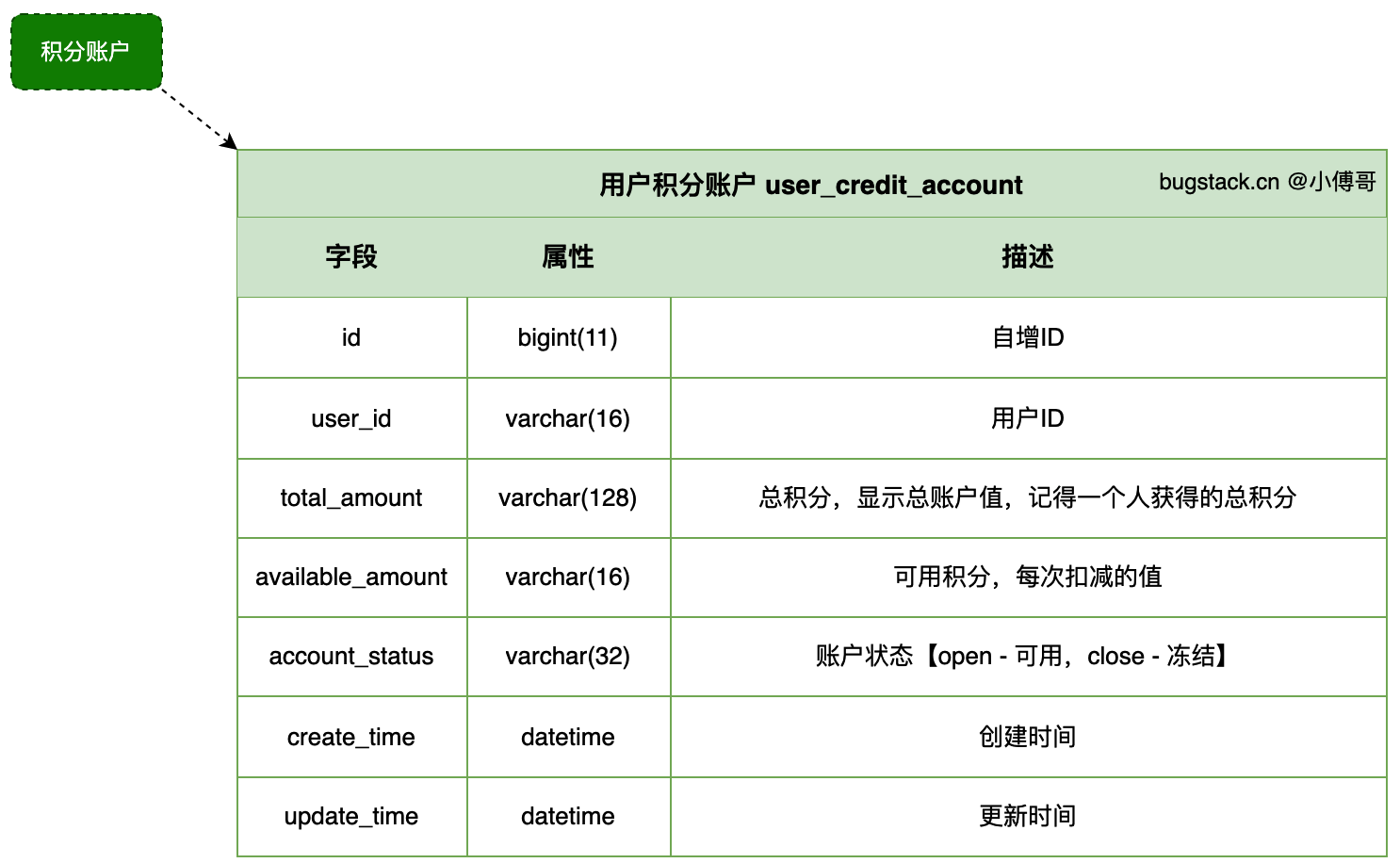
- 总积分记录一个用户获取的全部积分值
- 可用积分,消耗值,每次扣减都会扣减这个额度
- 账户状态,如果账户不可用,会被冻结。
积分发奖服务实现
设计用户活动积分流程,创建用户积分表,并开发用户抽奖积分奖品后,完成奖品发放流程,给用户增加积分。 用户的积分是一种中间媒介,抽奖可以获取积分奖品,签到可以获取积分奖品,还可以用积分兑换活动抽奖次数。通过这样的方式把整个抽奖流程闭环。 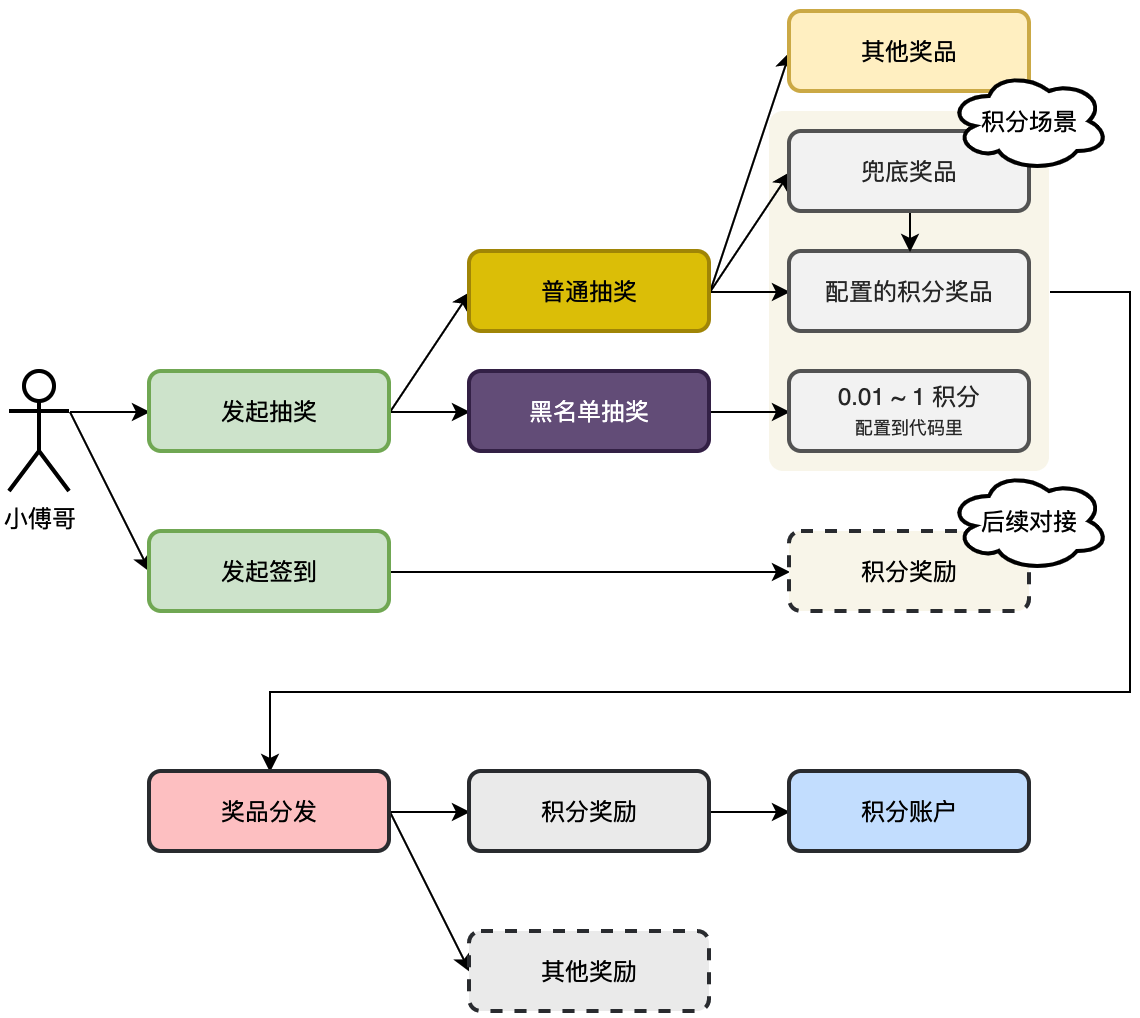
- 本节工程的实现流程为扩展 award 奖品分发服务,由 trigger 触发器的 MQ 消息调用奖品发放。
- 注意,我们在设计抽奖的时候,奖品的积分值发放为传递的透传参数和奖品本身的配置两种。也就是说,如果黑名单这类抽奖,透传了 0.01 ~ 1 积分,那么就固定用这个配置,否则就用奖品表自己的配置。
奖品发放
奖品是有多种类型的实现,可以把这些实现定义为策略。策略的唯一标识就是奖品表中的award_key值,这个值可以作为bean对象的名称。那么在拿到奖品ID,反查到奖品key时, 就可以获得对应的bean对象,而不是使用if...else的判断。本质就是策略模式的动态化实现。
- 针对不同类型的奖品,实现该接口并使用 @Component 注解注册为 Spring Bean,例如 UserCreditRandomAward 类:
@Component("user_credit_random")
public class UserCreditRandomAward implements IDistributeAward {
// 实现发放积分奖品的逻辑
}
其中注解中的 "user_credit_random" 即为策略的唯一标识,对应奖品表中的 award_key 字段。
- 在 AwardService 中,通过构造函数注入 Map<String, IDistributeAward> 类型的 distributeAwardMap :
private final Map<String, IDistributeAward> distributeAwardMap;
public AwardService(IAwardRepository awardRepository, SendAwardMessageEvent sendAwardMessageEvent, Map<String, IDistributeAward> distributeAwardMap) {
this.awardRepository = awardRepository;
this.sendAwardMessageEvent = sendAwardMessageEvent;
this.distributeAwardMap = distributeAwardMap;
}
Spring 会自动将所有实现了 IDistributeAward 接口的 Bean 放入该 Map 中,键为 Bean 名称(即 award_key ),值为策略实例。
- 奖品发放流程
- 获取 award_key :通过奖品 ID 从数据库查询对应的 award_key
String awardKey = awardRepository.queryAwardKey(distributeAwardEntity.getAwardId());- 获取策略 Bean :通过 award_key 从 distributeAwardMap 中获取对应的策略实例
IDistributeAward distributeAward = distributeAwardMap.get(awardKey);- 执行发放逻辑 :调用策略实例的 giveOutPrizes 方法发放奖品
distributeAward.giveOutPrizes(distributeAwardEntity);
对于其他奖品:虚拟产品(积分)可以直接发放,真实产品内部的话还好说一个厂子几步路送过去或者让他们自己领 然后核销。 外部类似于跨省(肯定需要走运单,类似于发快递),前提你们系统有物流能力,调用物流接口生成运输单,场地打印运输单装起来发走等等。 就是你们系统自己的业务能力了。假如没有物流能力 ,那就说你们和第三方快递谈了合作,统一发件(最简单的就是你们每天固定时间有人拉个小车去快递站点,把奖品发出去。 物流单号的话可以通过面单条形码,通过app快速识别登记),或者调用第三方发件接口等等。
积分领域调额服务
增加用户积分领域模块,开发积分调额接口。串联行为发奖动作,发放用户积分奖励。这是一整条流程,在设计积分领域模块的时候,要考虑这块模型的功能添加都有哪些,将来可能会存在的接口。如;把对积分账户的增加,抽象为调额。将来使用积分还可以定义出积分消费的接口。我们通过不同的接口做职责的划分。 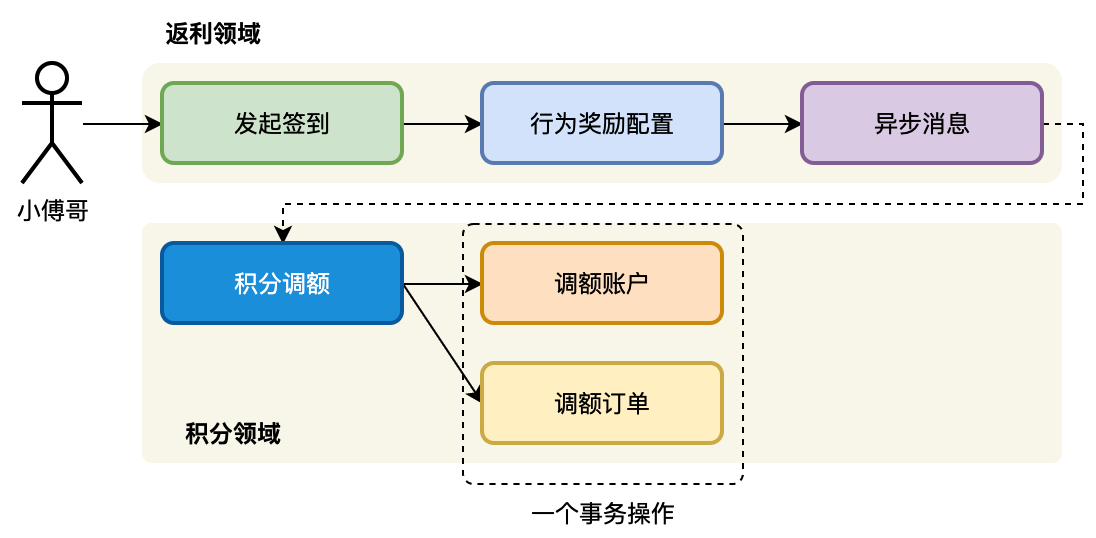
- 设计、定义和开发出积分领域模块,增加积分调额接口。
- 对接返利异步消息,完成积分额度的增加。
积分场景的实现是用户通过交易实体对象,发起交易行为的订单创建。用户创建订单是决策命令,订单创建完成是领域事件。领域事件是结果态,最终的结果。
Redis加分布式锁
通过 Redis 分布式锁(RLock)锁定用户积分账户的特定操作(积分调整等),防止多个并发请求同时修改同一账户。以个人用户为维度加锁,因为个人的用户频次不会很高。 也可以减少对数据库的并发表记录的加锁压力。
RLock lock = redisService.getLock(Constants.RedisKey.USER_CREDIT_ACCOUNT_LOCK + userId + Constants.UNDERLINE + creditOrderEntity.getOutBusinessNo());
- userId:不同用户的积分操作互不影响,可并行执行,避免全局锁导致的性能瓶颈。
- creditOrderEntity.getOutBusinessNo():外部业务编号(如订单号)确保同一笔业务(如同一订单的积分调整)不会被重复处理,即使请求重试或并发触发。幂等性保障。
加锁的意义:在高并发情况下, 有可能下面的操作会因为我们的系统设计(异步消息+多线程处理)导致两个异步消息被不同的机器同时消费: 一个用户分别进行了签到, 然后同时又支付去购买更多次数. 这些操作的底层数据库更新不会立即执行因为我们使用了异步消息。 由于签到和make payment是两个不同的服务, 所以存在可能性这两个异步消息同时到这里, 而且打比方这个用户是一个新用户, 数据库中没有他的 raffleActivityAccount. 这种情况下, 由于我们使用了异步消息, 而两个消息同时到这里, 会导致两个线程同时尝试创建账户, 但是由于数据库的唯一索引, 会导致其中一个线程失败抛异常。 但是在实际业务中, 我们不希望后台因为这些操作崩掉因为是可以通过加锁来避免: 保证同一个用户的操作是串行的, 也就是说, 一个用户的操作必须等到上一个操作完成, 这样就避免的唯一索引异常。
举例说明redis加分布式锁的好处
| 前言 | 请求A和请求B同时尝试为用户123更新积分账户和奖品记录。 |
| 无锁时操作 | 无锁时:两个请求可能同时通过 dbRouter.doRouter 路由到同一数据库分片,并执行以下逻辑: 1、同时查询用户积分账户(假设此时账户不存在)。 2、同时尝试插入用户积分账户(userCreditAccountDao.insert)。 |
| 无锁时操作会产生的问题 | - 唯一索引冲突:如果数据库表中 user_id 是唯一索引,两个插入操作会触发 DuplicateKeyException,导致其中一个请求失败。(尽量去避免这种情况) - 数据不一致:若未正确处理异常,可能导致积分账户未正确创建,但奖品记录却被标记为已发放。 |
| 加锁后效果 | 加锁后:通过 RedLock 保证同一时间只有一个请求能执行关键逻辑。 - 请求A先获取锁,执行查询→发现无账户→插入成功。 - 请求B在锁外等待,直到锁释放后,再查询时发现账户已存在→直接更新积分。 锁的粒度是用户级别(Constants.RedisKey.ACTIVITY_ACCOUNT_LOCK + userId),既避免了全局锁的性能问题,又确保了用户维度的操作原子性。 |
查询与更新分离
| 分类 | 详情 |
|---|---|
| 原代码逻辑问题(无锁) | int updateAccountCount = userCreditAccountDao.updateAddAmount(userCreditAccountReq); if (0 == updateAccountCount) { userCreditAccountDao.insertUserCreditAccountReq(); // 直接尝试插入 } |
| 原代码逻辑问题举例 | 1. 假设用户 123 的积分账户存在,但两个请求同时触发更新; - 请求 A 和请求 B 同时调用 updateAddAmount。 - 数据库发现表中该用户账户不存在,可能都成功执行(例如积分分别加 10 和 20,最终结果可能是 30 )。 2. 如果账户不存 - UPDATE 操作返回 0 行影响: - 两个请求都会尝试 INSERT,导致唯一索引冲突(DuplicateKeyException )。 |
| 原代码(先 UPDATE 后 INSERT 会阻塞)场景与问题 | 假设 user_credit_account 表中 user_id 是唯一索引,且当前没有 user_id=123 的记录。两个并发事务A,B同时执行以下操作 1、场景复现 事务 A 和事务 B 同时执行以下操作: - UPDATE user_credit_account SET amount = amount + 10 WHERE user_id = 123; (因 user_id=123 不存在,UPDATE 影响 0 行 )- 接着尝试插入:INSERT INTO user_credit_account (user_id, amount) VALUES (123, 10); 2、数据库锁发生了什么? 在可重复读隔离级别下,数据库会通过间隙锁(Gap Lock)防止幻读,具体行为如下: - 当执行 UPDATE 时:因 WHERE user_id=123 的记录不存在,数据库会在 user_id 的索引上找到一个合适的位置(例如,假设索引中存在 user_id=100 和 user_id=200 ,则 user_id=123 的间隙为 (100, 200) 是一个间隙 )。- 这个锁的目的是防止其他事务在 (100, 200) 范围内插入新的记录(比如 user_id=123 ),从而保证事务执行期间的数据一致性 。- 当执行 INSERT 时:插入操作需要获取一个插入意向锁(Insert Intention Lock )。 - 如果这个插入位置( user_id=123 )被其他事务的间隙锁 (100, 200) 覆盖,则插入意向锁会被阻塞,直到间隙锁释放。 3. 阻塞过程分析 - 事务 A 和事务 B 同时执行 UPDATE; - 两者都试图对 user_id=123 执行更新,但由于记录不存在,数据库为两者都加了同一个间隙锁 (100, 200);- 注意:间隙锁之间是兼容的(多个事务可以同时持有同一个间隙的间隙锁 ),因此此时不会阻塞; - 事务 A 准备插入 user_id=123,需要获取插入意向锁,但发现该锁被事务 B 的间隙锁覆盖,于是事务 A 阻塞,等待事务 B 释放间隙锁;- 事务 B 同样要插入,发现该锁也被事务 A 的间隙锁覆盖,事务 B 也阻塞,等待事务 A 释放间隙锁; - 结果:两者互相等待对方的间隙锁释放,形成死锁( 超时后 )。 4. 最终结果 - 唯一索引冲突:如果数据库检测到死锁,会回滚其中一个事务,导致其中一个 INSERT 成功,另一个因唯一索引冲突失败; - 超时:如果未触发死锁检测,事务可能因等待锁超时失败( 如 MySQL 的 innodb_lock_wait_timeout 默认 50 秒 )。 5、优化后的代码如何解决这个问题? 通过 Redis 锁串行化操作+查询先行,避免了对不存在记录的 UPDATE,从而规避了间隙锁的竞争。 |
| 优化后的逻辑 | UserCreditAccount userCreditAccountRes = userCreditAccountDao.queryUserCreditAccount(userCreditAccountReq); if (userCreditAccountRes == null) { userCreditAccountDao.insertUserCreditAccountReq(); // 先查询再插入 } else { userCreditAccountDao.updateAddAmount(userCreditAccountReq); // 直接更新 } |
| 优化后效果 | 逻辑先行:先明确判断用户账户是否存在,再决定插入或更新,避免盲目调用 UPDATE 后补插入。 优化效果:通过 Redis 锁串行化操作+查询先行,避免了对不存在记录的 UPDATE,从而规避了间隙锁的竞争。 结合锁机制:由于外层有分布式锁,可以保证查询 → 插入/更新的整个流程是原子的,彻底避免并发问题。 |
积分支付兑换商品
开发扣减积分、兑换sku商品所需的服务模块。让积分的获取、消费,形成逻辑闭环。
积分是衔接营销场景中各个功能模块的一个非常重要的手段,如;各项用户的行为 + 抽奖返利积分,积分兑换商品、积分兑换抽奖次数、积分支付抵扣、积分会员等级折扣等。 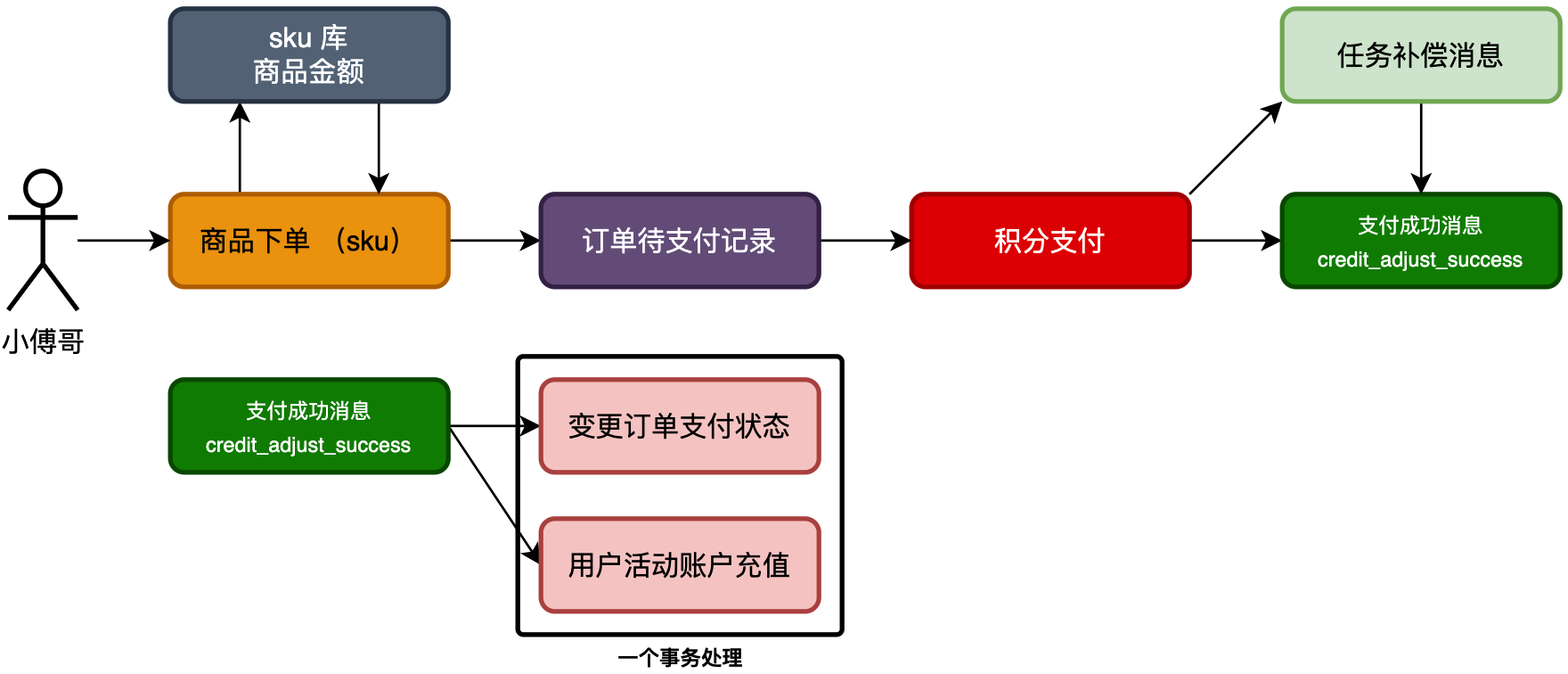
- 首先,对 sku 商品库增加积分金额,用于积分支付,而签到兑换类则无需关注金额。
- 之后,商品下单需要提供出交易策略;无支付交易和有支付交易。
- 最后,下单完成则进行积分抵扣,以及接收到支付成功消息,进行充值入账。
因为商品下单包括;签到返利 - 无支付,积分兑换 - 有支付,为了避免使用 if···else 的判断,可以增加支付策略逻辑,来处理自己的操作。 不同类型的交易策略实现类,通过构造函数注入到Map中
更新订单状态操作,是对订单从支付态更改为发货完成态。在数据库表更新的时候,有一个前置的判断,订单状态必须为 wait_pay 才能更新为 completed 否则不能更新。更新订单->更新总、月、日账户。
交易支付这部分,需要与发货解耦。异步发送消息,写入task任务表。监听消息,收到消息后异步发货。
- 待支付订单的创建与保留 : 在 AbstractRaffleActivityAccountQuota 的 createOrder 方法中,系统会先检查用户是否存在一个月内的未支付订单(状态为'wait_pay'),若存在则直接返回该订单;若不存在则创建新的待支付订单。
- 积分不足的检测与处理 :
- 创建订单前,系统会通过 activityRepository.queryUserCreditAccountAmount(userId) 检查用户积分是否充足,不足则抛出 USER_CREDIT_ACCOUNT_NO_AVAILABLE_AMOUNT 异常。
- 即使订单创建成功,在 CreditRepository 的 saveUserCreditTradeOrder 方法中实际扣减积分时,若因并发扣减导致积分不足,同样会抛出该异常并回滚事务。
- 未支付订单的再次使用 : 当用户再次尝试兑换时,系统会通过 queryUnpaidActivityOrder 方法查询到之前创建的待支付订单并返回,用户可以使用该订单继续支付流程。
- 异常处理与用户反馈 : 在 RaffleActivityController 的 creditPayExchangeSku 方法中,支付失败(包括积分不足)会被捕获并返回错误响应,但已创建的待支付订单会被保留
积分应用场景接口实现
以支持积分使用「商品、账户、兑换」对接前端诉求,在本节开发所需的接口。包括;串联前面章节中实现积分模块功能完成积分兑换case(串联的每一个服务都可以当做一个case看待,只不过我们的场景没有那么多,所以在工程搭建中去掉了单独的case模块,减少对象频繁转换)、sku商品查询、用户积分账户额度查询。 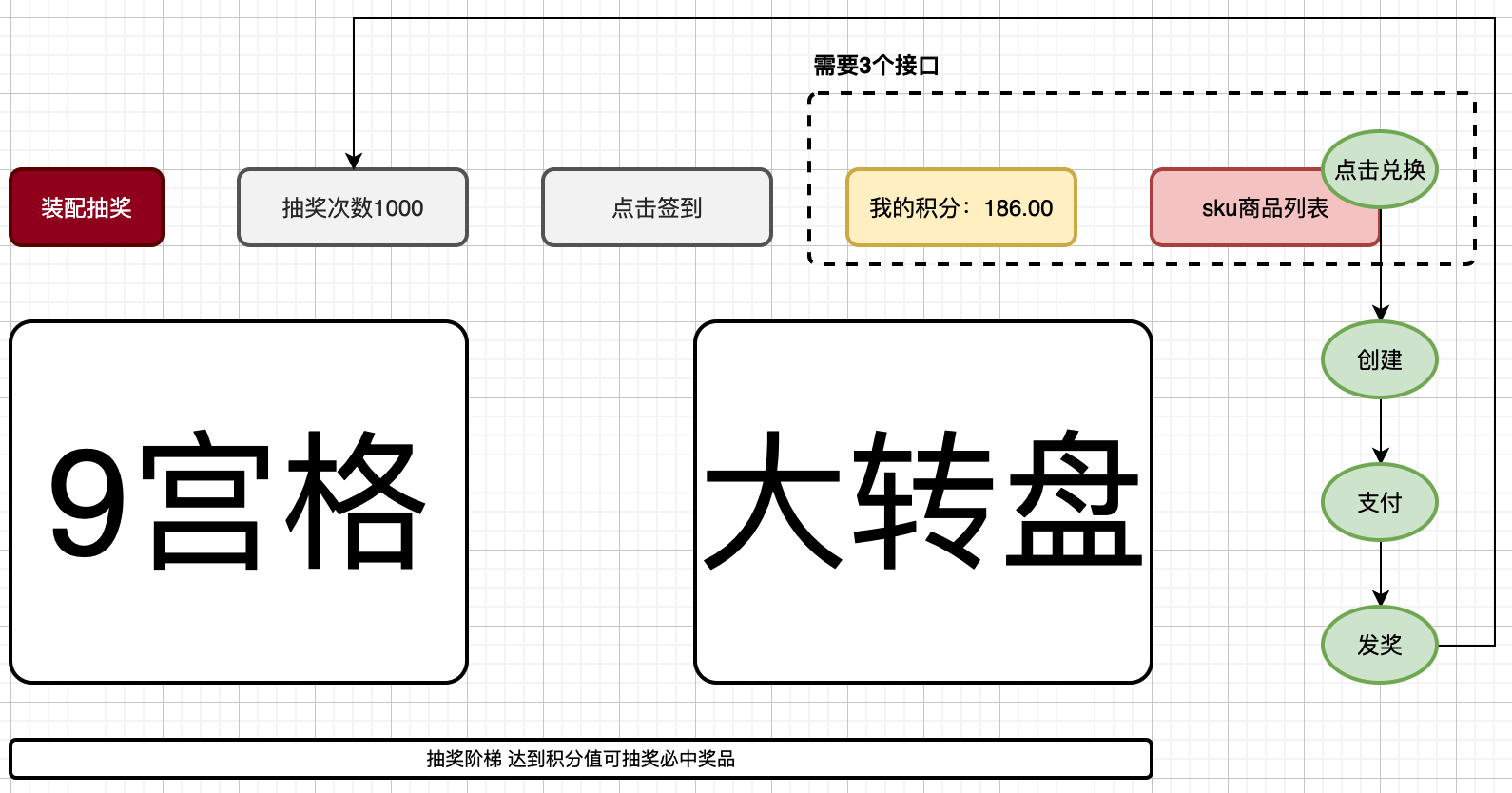
- 虚线框内为本节要为前端UI开发的接口,两个查询积分和商品,一个是操作兑换的处理。
- 注意,兑换的操作会对接口进一步完善,创建下单商品时候会返回未支付订单。这是因为从下单到支付是分开的步骤,可能下单完成,但支付的时候金额不足了「多笔下单场景消费积分」,也可能其他异常导致下单失败。这样的场景都需要把未支付的订单查询出来进行支付。
完善了活动额度下单接口,增加返回未支付订单。这样可以让后续的支付流程,直接通过未支付订单进行支付操作。 这里查询未支付订单的操作,是查询一个月有效期内未支付的订单,超过这个时间的则不在查询。也可以增加work扫描,超过1个月订单设置状态为过期。
订单创建流程, AbstractRaffleActivityAccountQuota.createOrder中实现
- 参数校验 :验证用户ID、SKU和业务单号
- 未支付订单查询 :查询用户一个月内的未支付订单,存在则直接返回
- 基础信息查询 :获取SKU、活动和次数配置信息
- 积分校验 :对于积分支付类型,检查用户积分是否充足
- 活动规则校验 :通过责任链模式( IActionChain )校验活动规则和库存
- 订单聚合对象构建 :组装订单相关信息
- 交易策略应用 :使用 CreditPayTradePolicy 设置订单状态为 wait_pay
- 订单保存 :将订单信息保存到数据库
积分支付流程,通过 CreditAdjustService.createOrder 方法实现
- 积分账户实体创建 :根据交易信息创建积分账户实体
- 积分订单实体创建 :记录积分交易详情
- 消息任务构建 :创建 CreditAdjustSuccessMessageEvent 事件消息
- 事务处理 :在事务中保存积分订单和任务记录
- 事件发布 :事务完成后发布积分调整成功事件
发货流程实现
- 消息监听 :监听 credit_adjust_success 主题的消息
- 消息解析 :解析积分调整成功消息,获取用户ID和业务单号
- 发货处理 :调用 raffleActivityAccountQuotaService.updateOrder 更新订单状态并完成发货
- 幂等处理 :处理消息重复消费的情况
引入Nacos+Dubbo框架
分布式技术栈框架 Nacos + Dubbo,用于微服务间调用,可以提高信息数据传输效率。
Dubbo 的底层通信是 Socket 而不是 HTTP 所以通信的性能会更好。
Dubbo 的实现接口,需要被 Dubbo 自己管理。所以 Dubbo 提供了 @DubboService 注解。
工程配置
address:如果配置的是 N/A 就是不走任何注册中心,就是个直连,主要用于本地验证的。代码中必须指定直连。@DubboReference(interfaceClass = IUserService.class, url = "dubbo://127.0.0.1:20881", version = "1.0.0") 如果你配置了 zookeeper://127.0.0.1:2181 就需要先安装一个 zookeeper。代码中对应 @DubboReference(interfaceClass = IUserService.class, version = "1.0.0") 另外,即使你配置了注册中心的方式,也可以直连测试。
原理分析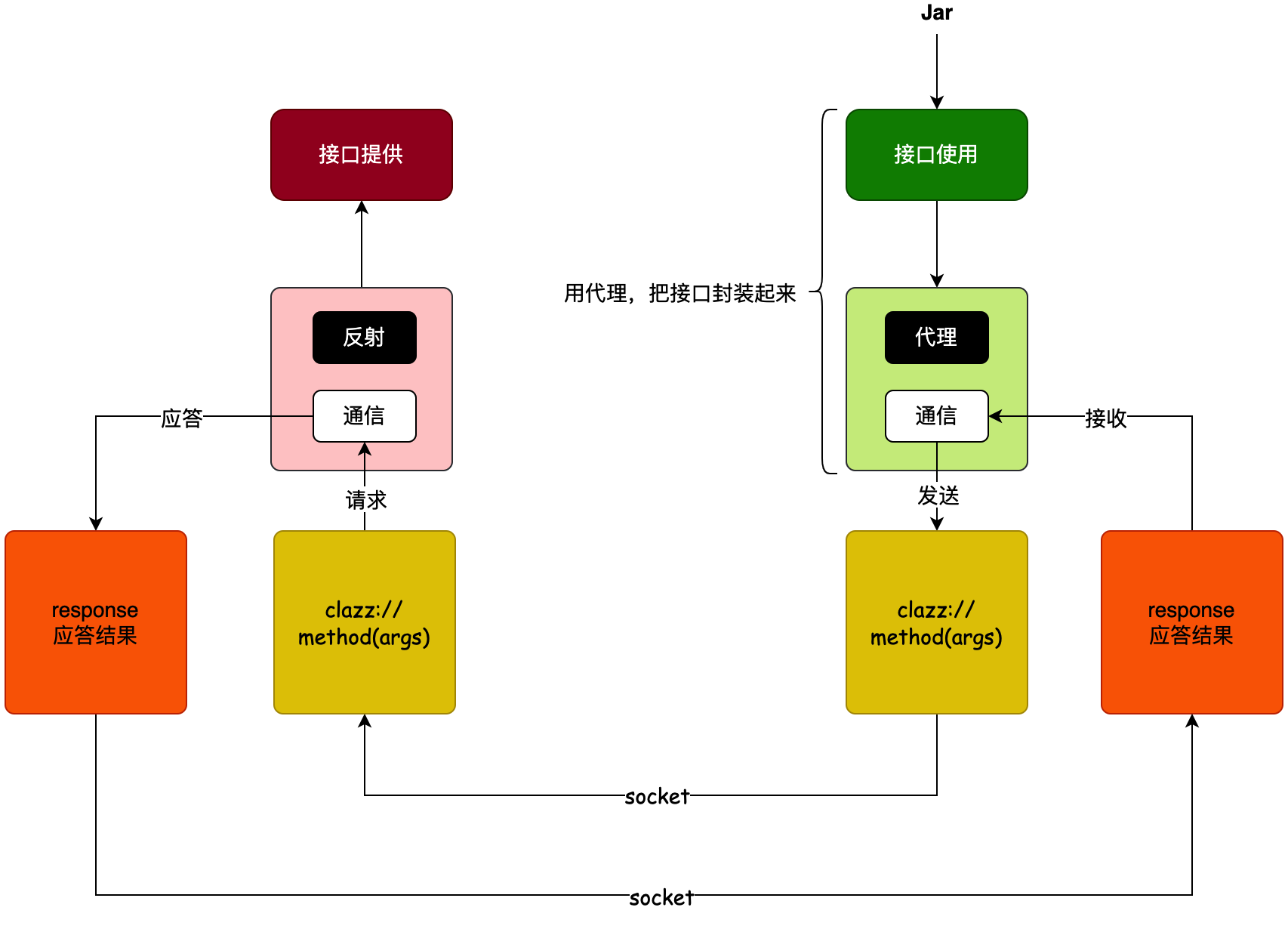
- 接口使用方,对接口进行代理。什么是代理呢,代理就是用一个包装的结构,代替原有的操作。在这个包装的结构里,你可以自己扩展出任意的方法。
- 那么,这里的代理。就是根据接口的信息,创建出一个代理对象,在代理对象中,提供 Socket 请求。当调用这个接口的时候,就可以对接口提供方的,发起 Socket 请求了。
- 而 Socket 接收方,也就是接口提供方。他收到信息以后,根据接口的描述性内容,进行一个反射调用。这下就把信息给请求出来,之后再通过 Socket 返回回去就可以了。
分布式动态配置活动降级
基于 Zookeeper 实现分布式动态配置中心服务,用于分布式应用节点系统中的环境属性值变更。这样我们可以让所有分布式系统中,类下的属性值做动态的调整,及时的对系统进行;切量、熔断、降级、黑白名单等用途。 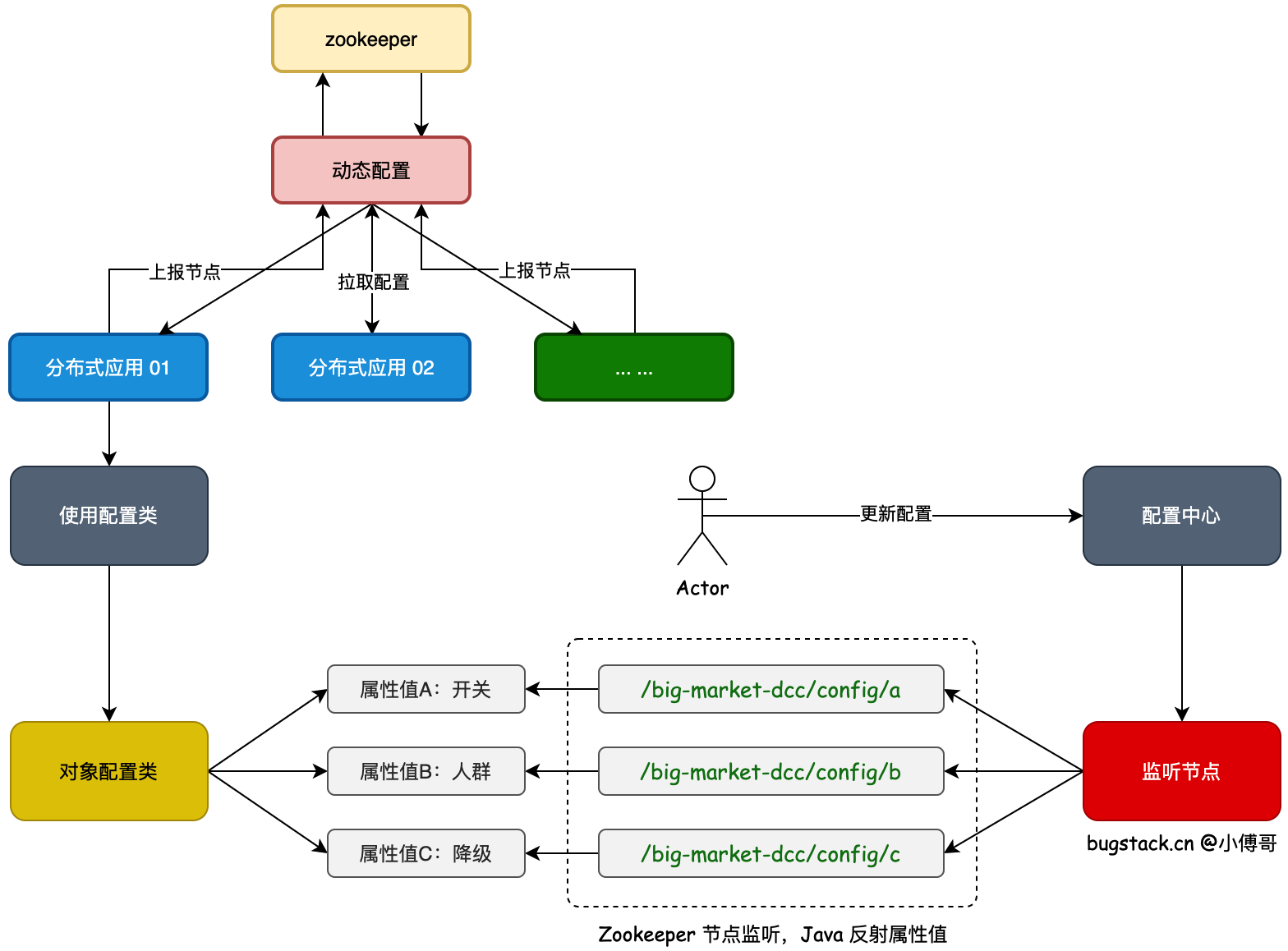 以Zookeeper为配置中心服务,基于 Zookeeper 的节点监听值变更机制,动态修改应用程序中属性值。
以Zookeeper为配置中心服务,基于 Zookeeper 的节点监听值变更机制,动态修改应用程序中属性值。
首先,我们需要定义出一个 Zookeeper 监听的配置路径,一般这个路径在配置中心中是申请的系统使用地址,以确保值的唯一。
之后,每个类对应的属性,需要映射出一个监听的节点。比如;Zookeeper 监听了 /big-market-dcc/config 那么类中 a 属性可以是 /big-market-dcc/config/a 这对这个路径设置的值,就可以被监听拿到了。
最后,把获取到的监听值,通过 Java 反射操作,把值设置到对应的属性上。这样在 SpringBoot 应用程序中,使用某个类的属性值的时候,就可以动态的获取到变化的属性值了。
在app模块,config配置下,增加 Zookeeper 配置,以及添加 DCC 动态配置服务。这个服务里会管理着添加了 @DCCValue 注解的属性信息,并对 Zookeeper 进行注册节点和监听值变化。
在 trigger 里提供 DCC 的管理,用于值的动态变更,以及在 RaffleActivityController 的抽奖方法中,增加一个动态的降级操作。
NODE_CHANGED事件监听器逻辑:
- 获取变更的节点路径(dccValuePath),从 dccObjGroup缓存中查找关联的 Bean 实例(objBean)。
- 通过反射获取 Bean 中与 ZK 节点同名的字段(如 ZK 节点路径为 /big-market-dcc/config/sku,则字段名为 sku)。
- 将 ZK 节点的最新数据(data.getData())写入 Bean 的对应字段,实现配置的动态更新。
上报流程思路: 在应用中通过api提供一个修改属性的方法,只要触发修改操作会调用zk的setData()方法,触发属性值上报到zk中。 当数据被更新到zk后,zk会通知所有监听该节点的客户端,该节点是 DCCValueBeanFactory 的监听器所监控的,监听器将会触发,读取更新的数据, 从map中找到对应的节点, 再更新节点对应的数据,从而实现动态配置的实时更新。
问题1:nacos前面用作注册中心了,为啥不直接采用主流的nacos做配置中心
- 进入企业中,并不是所有公司都用 nacos
- 不能因为一个动态配置服务,就要为不需要nacos的引入一套nacos再来维护
- Zookeeper 更加轻量,对于中小场景非常适合
- 也可以使用 nacos 替代 Zookeeper,在 dubbo 官网提供的注册中心,包括 nacos、Zookeeper,还有 redis
- 采用 Zookeeper 可以多学到一些额外的技术使用
分布式动态限流和熔断
加动态黑名单限流组件,通过访问动态限制将限流用户24H存入本地缓存,通过统一 Dcc 全局配置控制使用。并在方法上引入接口超时熔断组件。这两个东西都是分布式架构场景非常常用的手段。也经常在面试中提问,你的接口是如何保证可用性的,有什么手段对频繁访问的用户做出拦截处理。以及超时后的处理。 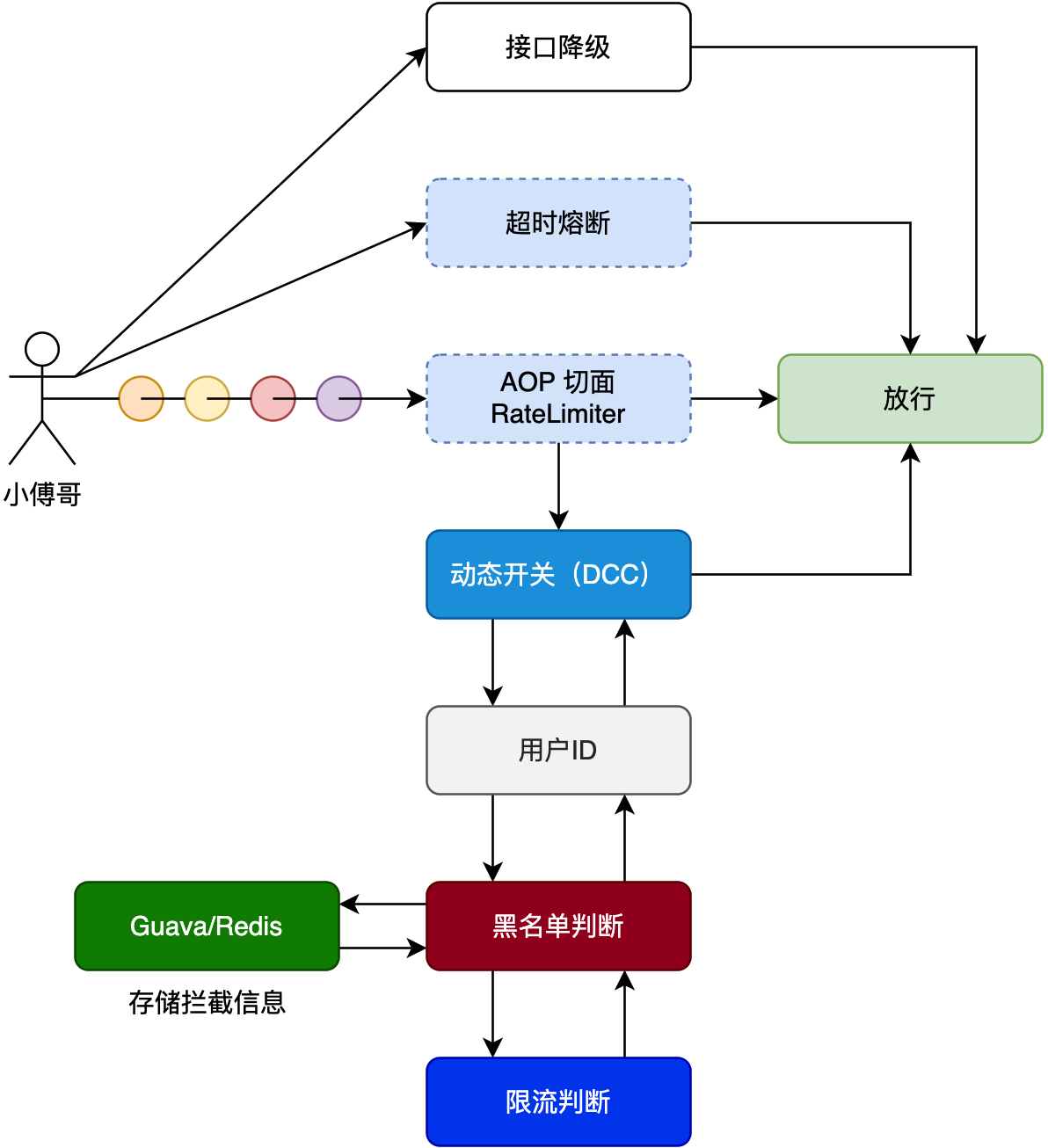 在之前通过 Zookeeper 实现的动态配置中心 @DCC 服务下,对新增加 RateLimiter 动态限流黑名单服务提供控制管理。
在之前通过 Zookeeper 实现的动态配置中心 @DCC 服务下,对新增加 RateLimiter 动态限流黑名单服务提供控制管理。
- 首先,因为我们引入切面了,那么上一节 @DCC 直接获取类操作属性的梳理就要考虑代理类的存在了。因为这时候被切面管理的类,在 Spring 中是一个代理对象,而不是原始对象,
- 之后,本节要增加的是 RateLimiter 限流,当一个用户频繁访问超过N次后,则会将这个用户加入黑名单列表,不允许在访问当前服务。直至过了超时时间从黑名单列表移走后才允许访问。
- 另外,本节还引入了接口超时熔断组件。降级、熔断、限流,这也是一套分布式微服务非常重要的手段。
RateLimiterAOP 为切面入口,管理所有被添加了 @RateLimiterAccessInterceptor 自定义注解的方法。注意被 AOP 管理的类,会成为代理类。 那么鉴于成为代理类了,在一个类里还要操作属性的值时,就需要获得原始的类 TargeClass。
设置通过DCC控制的限流开关:rateLimiterSwitch
限流的过程为检测单个用户访问频次是否达到限流配置值,达到后则进行限流黑名单记录,记录方式使用的是 Guava 本地缓存
分库分表数据同步ES
对于C端的场景来说,我们经常会采用分库分表的方案承载数据流量的压力,以用户ID为切分键,让用户的行为数据分散到各个库表中。那么在C端除了给用户提供数据服务以外,还需要给运营提供数据,但分库分表后的数据都已经散列到各个库表了,对于聚合查询就变得复杂,所以我们还需要另外一套方案。就是把分散在各个数据库表的数据,通过使用 canal 组件,基于 binlog 日志,把数据同步到 ElasticSearch 文件服务中再提供使用。 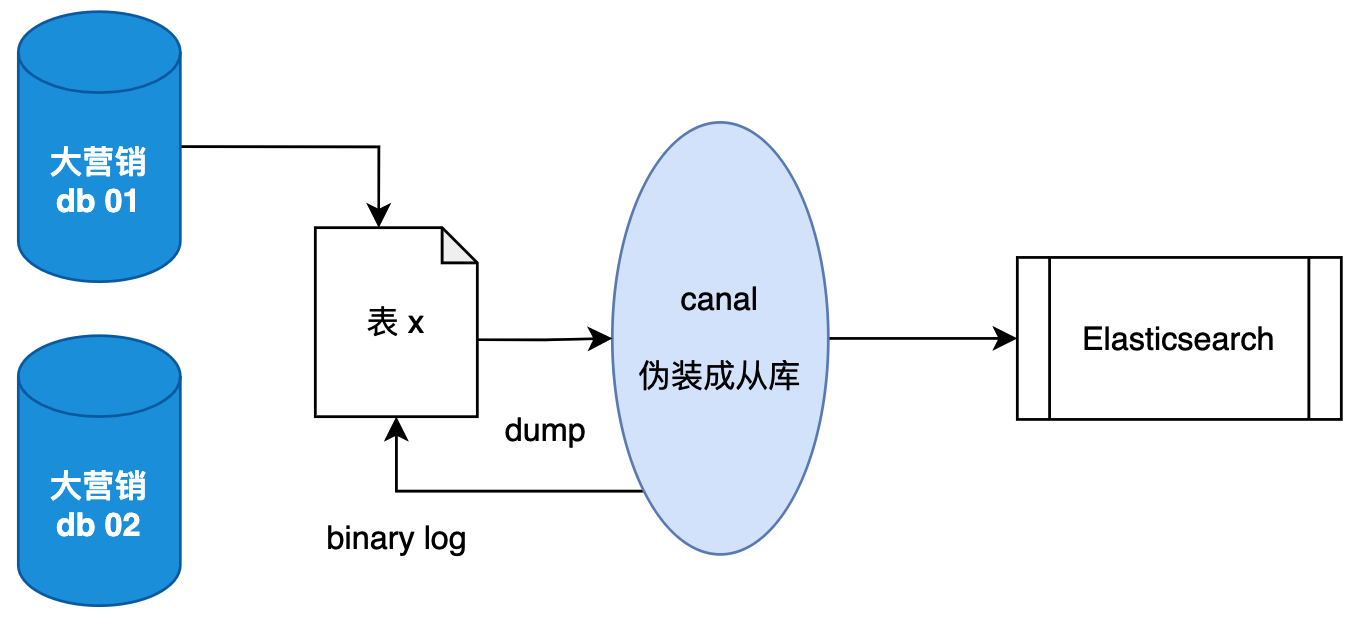 canal ,译为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。 它的工作原理是,canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议。在 MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal ) 这样 canal 再解析 binary log (binlog)进行配置分发,同步到 Elasticsearch 等系统中进行使用。 那么有了 canal 就可以把分库分表的数据同步到 Elasticsearch,提供汇总查询和聚合操作,也就不需要把轮训每个分库分表数据了。
canal ,译为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。 它的工作原理是,canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议。在 MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal ) 这样 canal 再解析 binary log (binlog)进行配置分发,同步到 Elasticsearch 等系统中进行使用。 那么有了 canal 就可以把分库分表的数据同步到 Elasticsearch,提供汇总查询和聚合操作,也就不需要把轮训每个分库分表数据了。
ES-ORM多数据源配置使用
目前已经在 MySQL 分库分表使用的基础上,加入了 canal 组件通过 binlog 日志把分库分表的数据同步 ElasticSearch 文件系统,那么接下来我们就需要让应用程序可以从 ElasticSearch 查询数据。也就是如何处理一个应用中多数据源的使用,同时要简化使用。 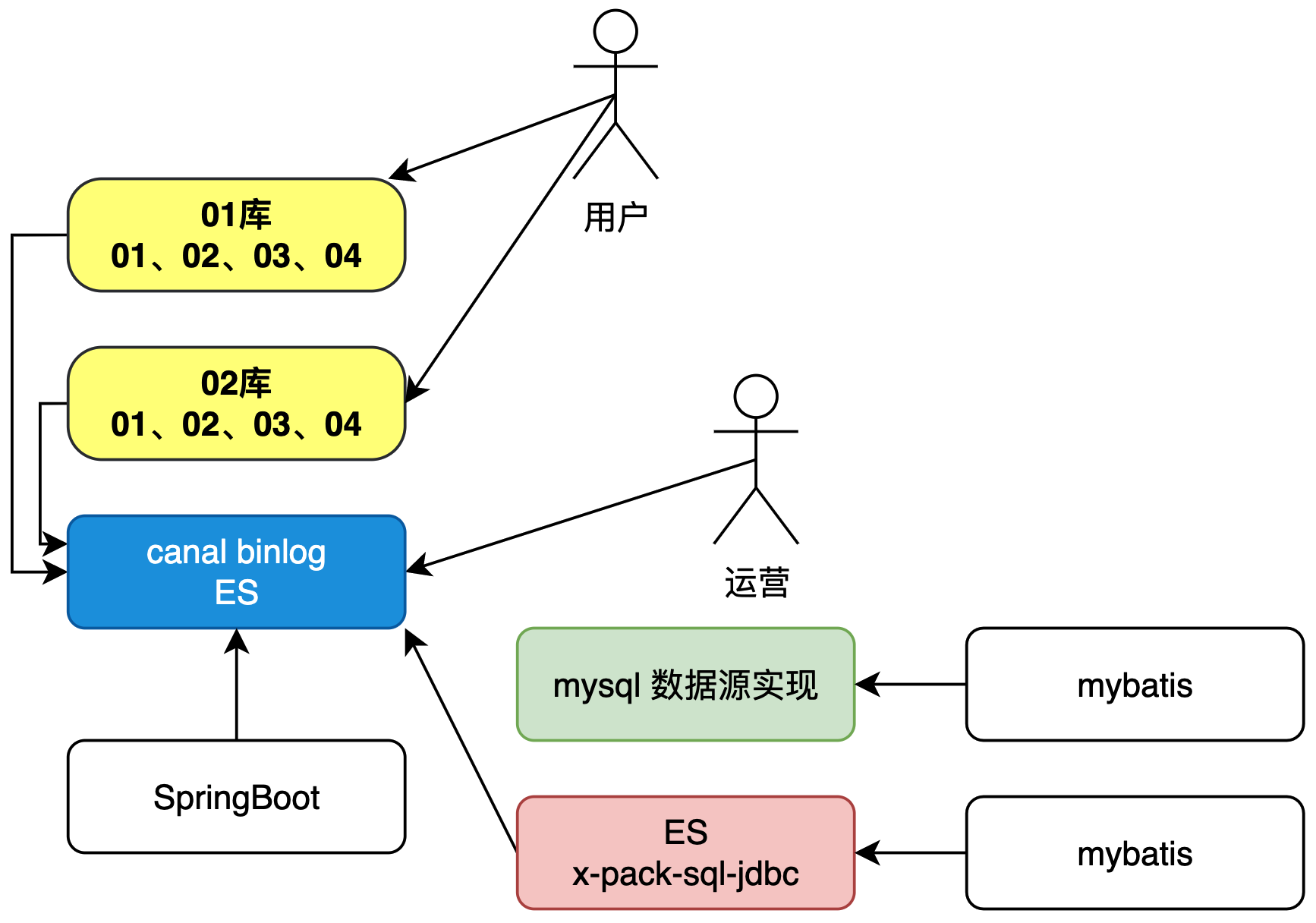
- 分库分表是对C端用户的,所有的C端行为一定是有用户ID的。
- canal 同步 ElasticSearch 是为了给运营端做数据聚合查询的,一般这类的查询是不做核心业务的,因为同步是有时效性的。
xxl-job分布式任务调度
增加 xxl-job 分布式任务调度服务,处理大营销中:发送MQ消息任务队列、更新活动sku库存任务、更新奖品库存任务定时任务。同时因为整个大营销是分布式部署,一套 big-market 会被多个应用实例一起部署,那么就会有多个实例上相同的一个任务要执行,这个时候需要增加抢占式锁,避免造成重复执行。重复执行可能导致无效的扫库或者重复发送MQ消息。 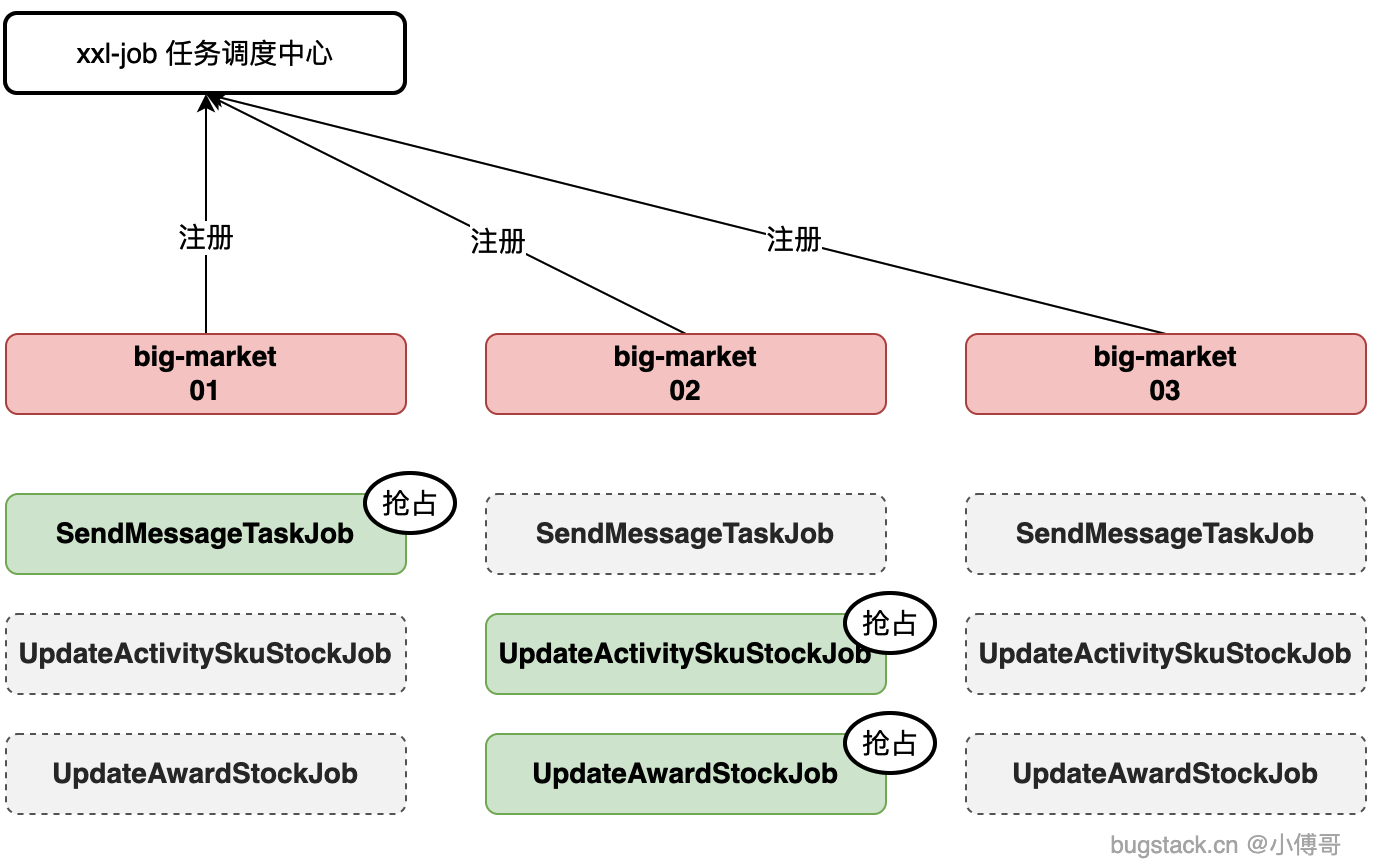 XXL-JOB 是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
XXL-JOB 是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
- big-market 01、big-market 02、big-market 03,也可以是更多的部署实例。
- 每个应用实例都是相同的任务,这些任务增加了 redis 分布式锁抢占,避免所有任务都被同时执行。分布式应用N台机器部署互备,任务调度会有N个同时执行,那么这里需要增加抢占机制,谁抢占到谁就执行。完毕后,下一轮继续抢占。
- 但不能为了只有一个执行而部署一套,部署多套的用途是为了互备,如果一个挂了还有其他的任务可以执行。这个就是分布式架构高可用的设计思路。
通过 XxlJobAutoConfig 类完成XXL-Job执行器的配置,主要职责是初始化 XxlJobSpringExecutor 实例并设置必要参数
使用 @XxlJob 注解标记任务方法,如 @XxlJob("SendMessageTaskJob_DB1");集成Redisson分布式锁防止任务重复执行。
任务调度是一个非常重要的功能组件,常作用于:定时清理数据 - 冷数据迁移、活动状态扫描 - 过期活动关闭、消息发送补偿 - MQ失败重发、支付掉单补偿 - 支付幂等重试,等各类场景都会用到任务调度组件。 它可以帮我们执行确定规则的业务或功能流程。
增强抽奖算法策略
在实际生产场景中,运营的奖品配置概率有时候百分位或者千分位,也就是小数点后有几个0,但有时候也有需要配置到万分位或者百万分位,来降低大奖的奖品概率配置。
对于不同概率的抽奖配置,我们也有为它设计出不同的抽奖算法策略。让万分位以下的这类频繁配置的,走O(1)时间复杂度。而对于超过万分位的,可以考虑循环对比,但在循环对比的中,还要根据奖品的数量设定出不同的计算模型。如;O(n)、O(logn) 如图; 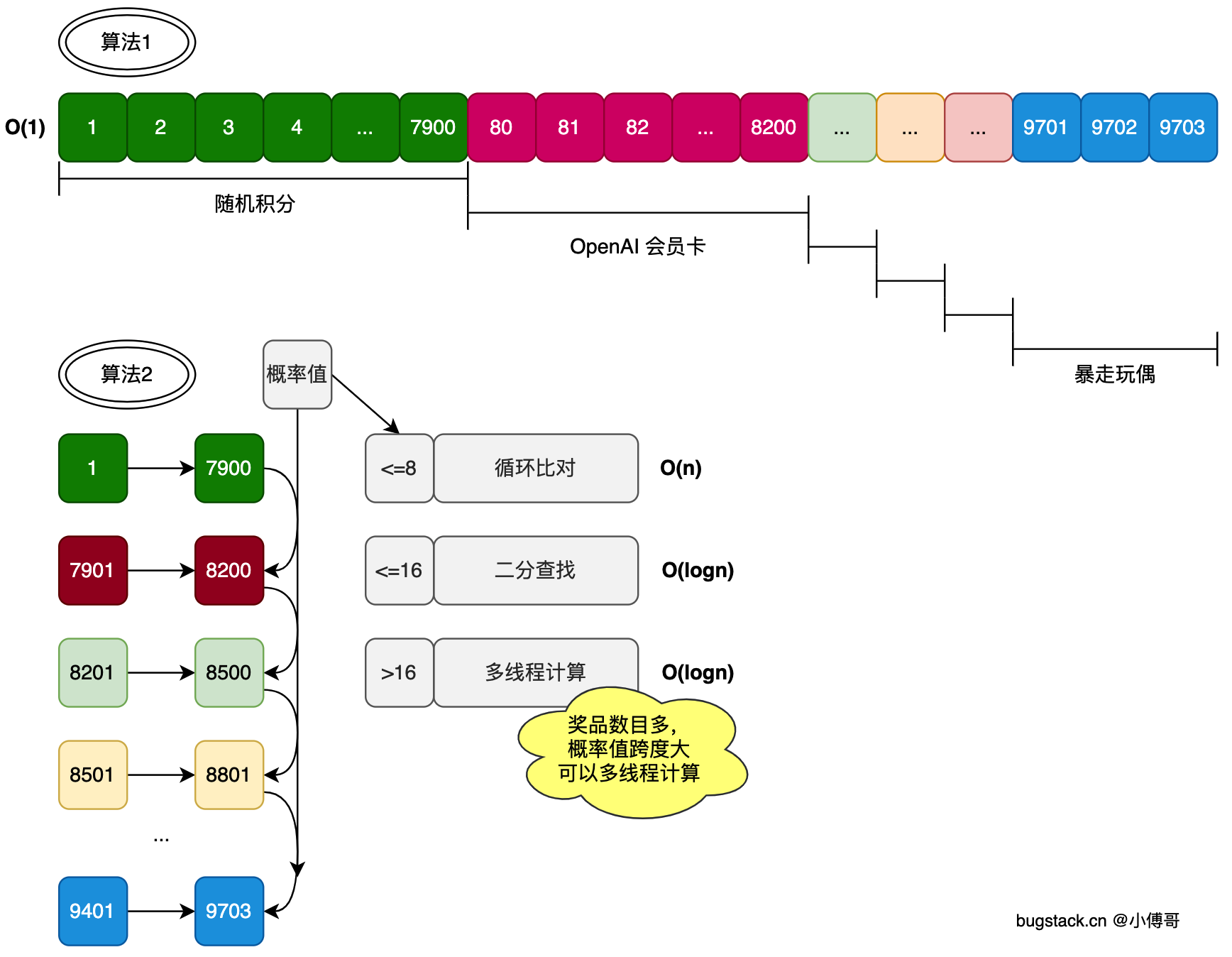 算法1;是O(1) 时间复杂度算法,在抽奖活动开启时,将奖品概率预热到本地(Guava)/Redis。如,10%的概率,可以是占了1~10的数字区间,对应奖品A。11~15 对应奖品B。那么在抽奖的时候,直接用生成的随机数通过对 map 进行 get 即可。
算法1;是O(1) 时间复杂度算法,在抽奖活动开启时,将奖品概率预热到本地(Guava)/Redis。如,10%的概率,可以是占了1~10的数字区间,对应奖品A。11~15 对应奖品B。那么在抽奖的时候,直接用生成的随机数通过对 map 进行 get 即可。
算法2;是O(n) ~ O(logn)算法,当奖品概率非常大的时候,达到几十万以上,我们就适合在本地或者 Redis 来初始化这些数据存到 Map 里了。那么这个时候就要把奖品概率,拆分为一个个有限定范围的格子区间。比如 1~7900代表一个奖品、7901~8200代表另外一个奖品,把这些数据存储到 Map<Map<Integer,Integer>,Integer> 在抽奖的时候通过产生的随机值来与这些范围区间依次进行对比。那么为了更好的优化抽奖算法,可以的分别对小范围的进行for循环、中等范围的二分查找、大范围的进行多线程计算。频繁开启多线程的资源也是一种消耗。
新增十连抽功能
后端
在现有抽奖系统中新增"十连抽"功能,允许用户一次发起10次连续抽奖,要求:
- 兼容原有单抽逻辑,不破坏现有功能
- 通过批处理 + 异步并行 + 缓存优化提升性能
- 保证高并发下的数据一致性和准确性
- DTO 层
ActivityTenDrawRequestDTO- 十连抽请求对象
ActivityTenDrawResponseDTO- 十连抽响应对象
- Domain 层
UserTenRaffleOrderEntity- 十连抽订单实体CreateTenPartakeOrderAggregate- 十连抽聚合对象
- Redis 常量
Constants.RedisKey.RAFFLE_DAY_COUNT- 每日抽奖次数缓存key前缀
- DAO 层
IUserRaffleOrderDao.batchInsert()- 批量插入抽奖订单IUserAwardRecordDao.batchInsert()- 批量插入中奖记录- 对应的 MyBatis XML 中添加了
<foreach>批量插入SQL
- Service 层
IRaffleActivityPartakeService.createTenDrawOrder()- 十连抽订单创建接口AbstractRaffleActivityPartake- 添加十连抽抽象模板方法RaffleActivityPartakeService- 实现十连抽额度校验和订单构建IAwardService.batchSaveUserAwardRecord()- 批量保存中奖记录
- Repository 层
IActivityRepository.saveCreateTenPartakeOrderAggregate()- 批量保存十连抽聚合对象IAwardRepository.batchSaveUserAwardRecord()- 批量保存中奖记录ActivityRepository / AwardRepository- 实现对应的批量保存逻辑
- API 层
IRaffleActivityService.tenDraw()- 十连抽接口定义
- Controller 层
RaffleActivityController.tenDraw()- 十连抽接口实现
创建十连抽参与活动订单聚合对象CreateTenPartakeOrderAggregate,包含用户ID、活动ID、额度信息、抽奖单实体等。
在IRaffleActivityPartakeService中添加实现十连抽接口方法,并在AbstractRaffleActivityPartake做具体实现
- 查询活动并进行状态和日期的校验
- 额度账户过滤&返回账户构建对象(十连抽需要确保至少有10次额度)
- 构建10个抽奖订单
- 保存十连抽聚合对象
在IActivityRepository中添加批量保存十连抽聚合对象的方法,并在infrastructure层做具体实现
- 数据库路由:
dbRouter.doRouter(userId)确保同一个用户的所有操作路由到同一个数据库分片,保证数据一致性。 - 通过编程式事务
transactionTemplate更新总账户、月账户和日账户(不存在月、日账户则创建),额度不足,则触发异常回滚。- 循环扣减而非批量扣减 :每次扣减1次,连续10次
- CAS机制检查 :每次更新后检查返回值是否为1,确保每次扣减都成功
- 即时失败处理 :一旦某次扣减失败,立即回滚事务
- 批量写入10条参与活动订单
在IAwardService中添加批量保存中奖记录,在AwardService做具体实现
- 构建消息对象
- 构建任务对象
- 构建聚合对象
- 存储聚合对象,即在一个事务下,保存更新用户的中将记录
在IAwardRepository中批量保存用户中奖记录,在AwardRepository做具体实现
- 创建用户奖品记录,任务
- 在一个事务内写入用户奖品记录,写入任务(发送奖品),更新抽奖单的状态
- 在一个事务内发送消息,更新task任务表中消息的状态
在 API 层添加十连抽接口,首先在IRaffleActivityService添加十连抽接口,并在trigger层做具体实现
- 参数校验
- 参与活动 - 创建十连抽订单
- 抽奖策略 - 并行执行十次单抽
- 线程池并发 :使用
ThreadPoolExecutor实现真正的并行抽奖,大幅提升性能 - Future模式 :通过
Future<RaffleAwardEntity>获取异步执行结果 - 业务隔离 :每次抽奖都是独立的业务单元,相互不影响
- 线程池并发 :使用
- 等待所有抽奖完成并收集结果
- 超时控制 :设置5秒超时避免线程无限等待
- 优雅降级 :单次抽奖失败不影响整体流程,用"未中奖"作为默认值
- 存放结果 - 批量写入中奖记录
- 返回结果 json 格式